整合了一部分给同学讲课时候提到的内容,顺带自己过了一遍基础x
Learning to Retrieve Reasoning Paths over Wikipedia Graph for Question Answering
SELF-RAG: Learning to Retrieve, Generate and Critique through Self-reflection
RAG是什么
RAG的全称是Retrieval-Augmented Generation,是一种融合检索和生成机制的模型架构,主要把它用于提升生成模型在特定任务上的表现。RAG效果主要为:
-提升模型回答准确性 传统的生成模型回答问题时基于内部的知识和训练数据,RAG则是结合检索机制从外部提取相关信息再基于这些信息生成回答。
-扩展知识范围 训练数据有限不可能覆盖所有领域或现实最新信息,RAG从外部数据库中检索相关信息来补充当前模型库外知识。
-优化生成质量 通过上文提到检索后的背景信息,可以让模型型可以生成更具体且相关的回答。 -提升鲁棒性 优化前面对复杂或者用户表达模糊的问题,直接生成很可能导致不准确回答,RAG帮助避免生成基于错误假设的回答。
现在模型在生成内容经常出现生成的信息与真实世界的事实不符,包括GPT3时期的错误引用数据(虚构refer、虚构作家和作品)、错误陈述和上下文理解错误。原因大致可以分为:缺乏实时信息、语境理解局限性、缺乏内在推理这三个,都可以通过RAG可以有效改善,但是RAG模型的关键在于它依赖搜索到的信息来提升回答质量,生成过程中的自我评估能力是有限的,搜索到的信息本身存在不准确或不充分的情况下RAG同样也会生成错误内容。
SELF-RAG
SELF-RAG在RAG的基础上增加了自我反思机制,在第一遍生成内容后,SELF-RAG能够通过Reflection tokens来评估生成内容的准确性和完整性。区别于上文的RAG,如果模型在反思过程中发现生成内容存在错误,SELF-RAG会重新检索更多的信息以补充或修正内容,这种机制能够在生成过程中多次迭代检索和生成,一直到达到比前文更高的准确性。
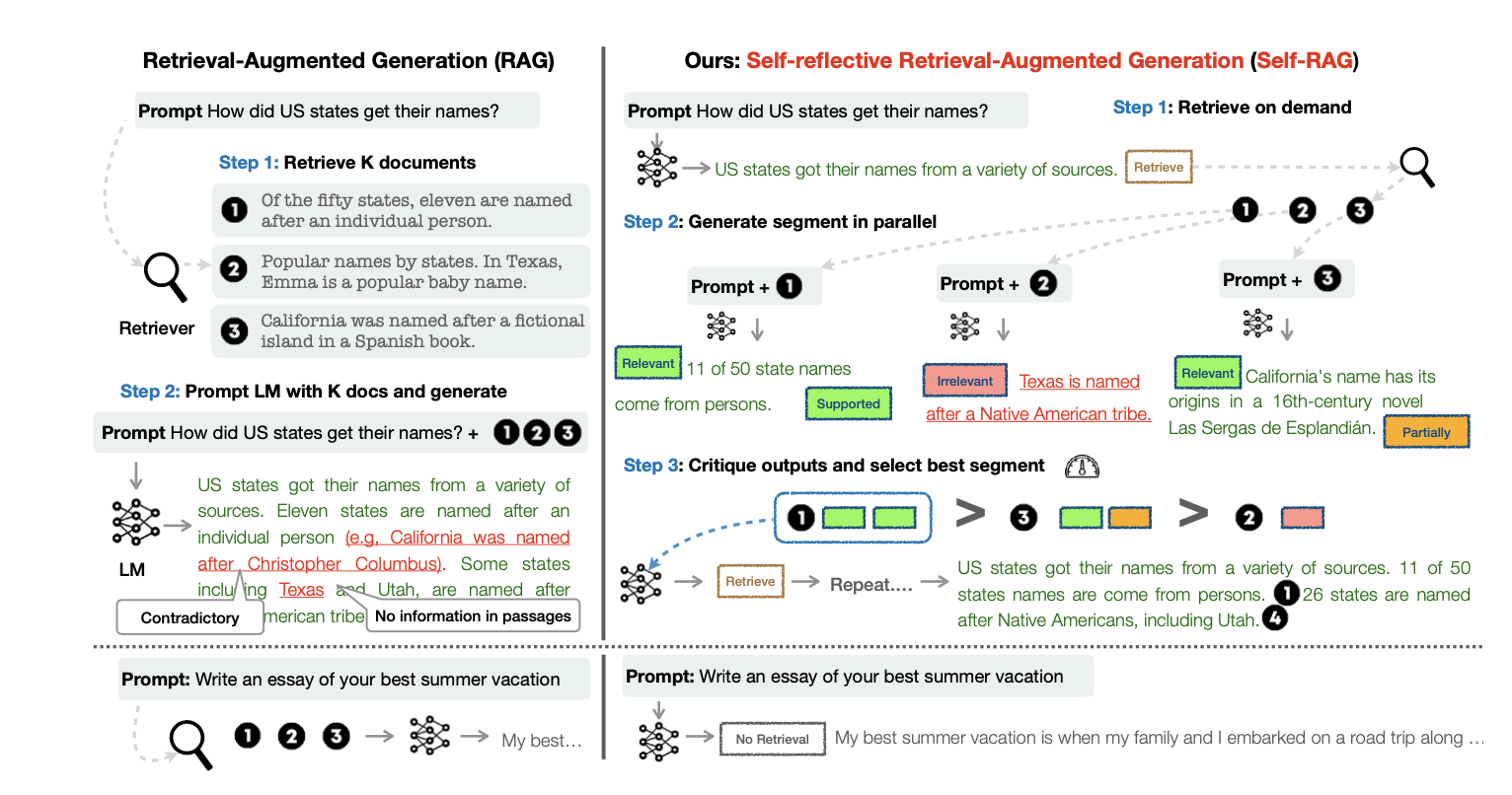
模型结构如图包括以下几个关键部分:
-
检索模块-在生成内容前,模型先从一个大型的外部库中检索与当前输入相关的信息,生成的查询用于在知识库中检索相关段落。
-
生成模块-检索到的信息被用作Generator的辅助输入,利用这些信息生成内容。
-
自反思机制-在生成内容后引入自反思机制,模型通过Reflection Tokens对生成的内容进行自我检查,判断生成的内容是否准确和是否需要进一步的补充。在每一个生成步骤中通过输入一个Retrieve Token来判断是否需要从外部检索,如果认为不需要检索则继续正常生成;如果需要则调用检索器获取相关的文本。
-
模型对于每一个检索到的文本片段会生成相关性评估的ISREL Token,用于标记检索到的片段是否与当前生成任务相关;接下来模型将生成另外一个ISSUP Token来评估生成的内容在有多大程度上得到了检索片段的支持。最后收尾部分模型将通过生成一个效用评估的ISUSE Token来对整体生成内容进行打分。
-
迭代-模型可以多次迭代检索和生成的过程最终生成更加准确和一致的内容。
SELF-RAG训练方法步骤大致分为四部分。
SELF-RAG采用了端到端的训练方式,在训练过程中的检索、生成、反思都是联合优化的。训练过程中模型使用了带有标注数据的监督学习方法,用于训练的数据包括了输入、期望的输出、可能的检索信息。自我反思机制是SELF-RAG的核心部分,在该部分的训练中模型通过Reflection Tokens来评估内容的质量,模型会学习什么时候需要进行额外的检索和什么时候需要修正生成的回答。模型将经历多次迭代来逐步改善检索及生成策略,每次迭代中都会根据Reflection Tokens的反馈调整行为。
代码实现

- 生成器语言模型-M
- 检索器-R
- 段落集合-{d1,d2,…,dN}
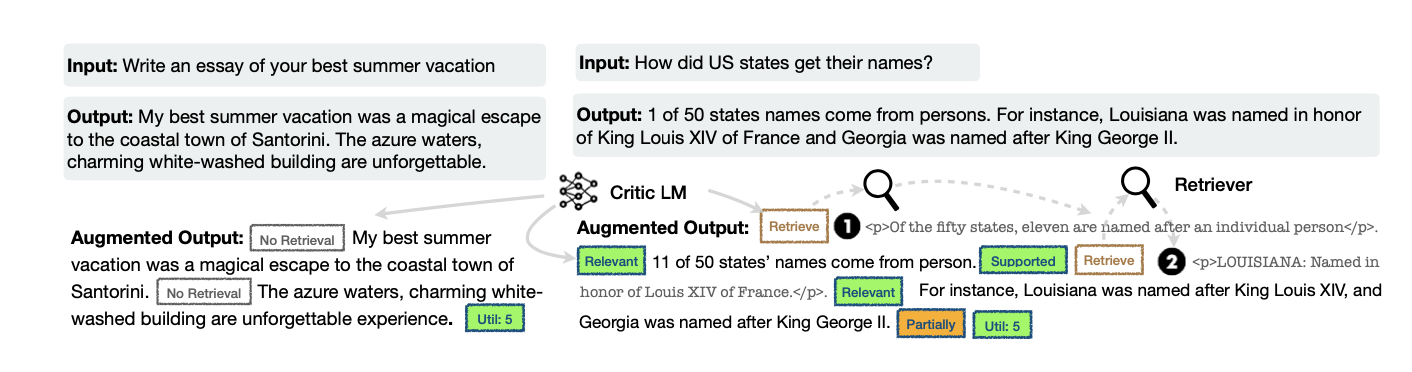
输入:接收输入提示 ( x ) 和之前生成的文本 (y<t) ,其中(y-t)是模型基于本次问题生成的文本?
检索预测:模型 ( M ) 预测是否需要检索(Retrieve),基于 ( (x, y<t) )。
检索判断:
如果 ( Retrieve ) == 是:
-
检索相关文本段落:使用 ( R ) 基于 ( (x, y<t) ) 检索相关文本段落 ( D )。
-
相关性预测:模型 ( M ) 预测相关性 ( ISREL ),基于 ( x ),段落 ( d ) 和 ( y<t ) 对每个 ( d ) 进行评估。
-
支持性和有用性预测:模型 ( M ) 预测支持性 ( ISSUP ) 和有用性 ( ISUSE ),基于 ( x, y<t, d ) 对每个 ( d ) 进行评估。
-
排序:基于 ( ISREL ), ( ISSUP ), 和 ( ISUSE ) 对 ( y<t ) 进行排序。
如果 ( Retrieve ) == 否:
-
生成下一个段落:模型 ( M ) 基于 ( x ) 生成 ( y_t )。
-
有用性预测:模型 ( M ) 预测有用性 ( ISUSE ),基于 ( x, y_t ) 进行评估。
还在施工x
还在施工