一个传统的rag,语料选择的是罗马历史专著,记录一下流程和踩到的坑,完整代码打磨一下弄成ui格式的就传(。
数据处理
因为是书的格式,所以拿正则表达式识别章节标题,再通过分段将长文本拆分为小结构块,切好的每个章节再细分段落,用BERT分词器将段落合并控制在一定token长度,我这里设置的是300,看一定的语义连贯性来判断是不是前段的延续。
用KeyBERT生成每个文本块的关键词,选tpo5调用SpaCy的transformer -en_core_web_trf来抽取命名实体,因为是历史类就包含了日期人名地名组织,最后每个chunk最终用JSONL格式保存,每条记录包括了chunk_id 所属章节 原文 关键词 命名实体、时间。
处理好chunk转换为向量表示。
对每个chunk构建带有结构提示的输入字符串,格式包括章节&关键&实&正文文本,用 SentenceTransformer(MiniLM-L6-v2)对所有文本构造向量表示,选这个的原因是体积小和速度快。colab用了FAISS建立L2距离索引把所有嵌入向量加入索引,因为想在后续检索阶段实现高效近似ANN。
SBERT 模型对chunk进行编码得到高维稠密向量表示,这些嵌入向量在语义空间中能够捕捉文本含义的相似性。代码所示用 faiss.IndexFlatL2() 创建基于 L2 欧氏距离的索引结构,将所有向量加载进索引。⭠ 虽然IndexFlatL2 是精确检索索引,但是FAISS本质上支持多种 ANN 索引类型。
这里就跑到了faiss和json文件。
[{"chunk_id": "1\n\n\nNew_Rome_and_the_New_Romans_0", "part_chapter": "1\n\n\nNew Rome and the New Romans", "text": "New Rome", "keywords": ["rome", "new"], "entities": ["New Rome"], "date_hint": ""}, {"chunk_id": "1\n\n\nNew_Rome_and_the_New_Romans_1", "part_chapter": "1\n\n\nNew Rome and the New Romans", "text": "On 11 May, 330, the sun, rising behind the Asian hills across the Bosporos, shone for the last time on the ancient city of Byzantion. On that day, the emperor Constantine rededicated the city to himself and to the Fortune of Rome. Henceforth, Byzantion became Constantinople and, as New Rome, it would change the course of history. While the city below lay still in the predawn shadow, the sun reflected off its highest point, a colossal statue of Constantine himself. This was a gilded bronze nude with rays emerging from his head, a spear in his left hand, and a globe signifying universal dominion in his right. Standing atop a column of purple stone that was almost forty meters tall and banded with victory laurel wreaths, the colossus was a repurposed Apollo. It reinforced the emperor’s long association with the Solar God and the first emperor of Rome. Over three centuries before, Augustus had chosen Apollo to project the serene power, eternal youth, and classical order of his new golden age. Constantine’s statue alluded also to the colossus of Sol that stood beside the Coliseum in Rome and gave it its name, and it linked New Rome to nearby Troy, the ancient Roman homeland whose patron deity was Apollo. Constantine and his City thus picked up the thread of an old history: the Romans, children of Aeneas and heirs of Augustus, had returned home. Stories soon circulated that Constantine had brought his colossus from Troy and had intended to found his City there but was diverted by an apparition to the more advantageous location of Byzantion.1", "keywords": ["constantine", "rome", "constantinople", "roman", "romans"], "entities": ["Troy", "that day", "Apollo", "New Rome", "City", "Rome", "Sol", "Byzantion", "three centuries", "Byzantion.1", "Augustus", "Aeneas", "11 May, 330", "Constantine", "Constantinople"], "date_hint": "11 May, 330"},
之前也做过类似的rag系统,当时用的是TF-IDF,这个是基于词频统计的文本特征提取方法来衡量一个词对某篇文档的重要性,但是它不考虑词的语义,只统计频率和分布,适用性很低而且无法理解上下文。
这次用的KeyBERT + SBERT,SBERT对原始 BERT 的结构改进能可以高效计算句子或短语的向量表达,KeyBERT 利用 SBERT 生成的句子级语义嵌入,把文档和候选关键词统一编码,再计算二者的语义余弦相似度。比起之前做的TF-IDF,能识别语义等价但表面不同的词组&支持 n-gram 短语建模,不局限于单词&通过计算嵌入间的向量相似度,而不是之前那样的频率来获取含义上最相关的关键词。
colab大失败
最初的planA是基于colab+OpenAI GPT 模型,拼接向量检索返回段落到 prompt然后调用模型回答,拿Gradio UI搭建。遇到的问题太多了遂记录:
-
调用
.launch()时的Colab默认只展示启动日志,不是直接嵌入式展示前端 UI,大陆连梯子上Colab的网络太差了一直在连接中。 -
使用
submit_btn.click(rag_pipeline, inputs=[query_input], outputs=[answer_output, refs_output])时发现了rag_pipeline函数必须始终返回两个 HTML 字符串不然Gradio会抛出错误,我测试的时候调用返回不完整整个交互流程就会中断,调试反馈也不够友好。 -
我采用的是新版 OpenAI Python SDK(>=1.0.0),看以前文章提供的代码使用了旧版接口,
openai.Embedding.create(),新版中Embedding模块变为了embeddings,create方法改为小写:response = openai.embeddings.create( input=query, model="text-embedding-3-small" ) -
在Colab上似乎无法稳定地OpenAI API 密钥…….
本地部署
换本地部署了,最初的想法是
User Query ↓ Query Embedding(同维度匹配 rag_index.faiss) ↓ FAISS 检索(返回 top-k chunk_id) ↓ 根据 chunk_id 从 rag_metadata.json 提取文本段 ↓ 拼接 Prompt → 传入GPT
跑完第一遍发现了很多问题,这个方案只靠语义匹配无法应对低相关词or特定术语,特别是历史这种术语多的,FAISS向量检索后直接拼接最相似的top-k文本的召回度也不高,而且直接拼接一堆 chunk按向量相似度排序,不管段落内容是否冗余。
得大改
第一个改动是对 query 做正则 + 关键词匹配,优先召回相关 chunk。为什么呢,因为用户query 如果是查士丁尼法典具体内容是什么?”这类问题就包含强指向性的显性知识项,但由于词嵌入模型倾向于捕捉语义相近文本,它召回的片段就可能没有明确包含,词向量模型无法对专有名词&具体信息建模得很好。
KEYWORD_PATTERNS = [
r"查士丁尼法典", r"Corpus Juris Civilis", r"拜占庭.*法律",
r"尼卡暴动", r"第四次十字军", r"君士坦丁堡陷落", r"曼齐克尔特战役"
]
def keyword_match(query, document_chunks):
matched_chunks = []
for chunk in document_chunks:
for pattern in KEYWORD_PATTERNS:
if re.search(pattern, query, re.IGNORECASE) and re.search(pattern, chunk['text'], re.IGNORECASE):
matched_chunks.append(chunk)
break
return matched_chunks
第二个改动是加入交叉编码器reranker,对 FAISS top-10 返回内容进行排序。为什么加这个,因为FAISS 是基于稠密向量的 ANN 检索,但是就像上面说的FAISS 检索返回的 top-k 内容只是语义相似,但不保证真正相关,加入reeanker可以保证 内容-意图对齐度最高的段落被优先考虑,因为我做的是历史类,错年份错事件会严重影响质量。
from sentence_transformers import CrossEncoder
reranker = CrossEncoder("cross-encoder/ms-marco-MiniLM-L-6-v2")
def rerank_chunks(query, faiss_chunks):
pairs = [[query, chunk['text']] for chunk in faiss_chunks]
scores = reranker.predict(pairs)
reranked = sorted(zip(scores, faiss_chunks), reverse=True, key=lambda x: x[0])
return [chunk for score, chunk in reranked]
*为什么要用WordNet获取关键词同义词,扩展关键词集合?
因为用户输入的关键词有限,而且这些词具有语义相关性,但是像我之前做的传统的关键词匹配无法覆盖这些语义变体。WordNet的作用就是扩展关键词集合 = 原始关键词 + 同义词 + 语义变体,让系统更有鲁棒性在不同表达的情况下也能判断文本与关键词的相关性。
*使用余弦相似度判断关键词与文本的相关度是为了计算语义相关性余弦相似度的意义是计算关键词向量与文本向量之间的夹角余弦值。值越接近 1 → 越相关;越接近 0 → 无关。允许判断即使关键词未直接出现在文本中,这段文本是否在语义上与关键词密切相关。
给文本加权的意思是每个文本片段都打上一个语义权重,weight = cosine_similarity(keyword_vector, text_vector)*在排序、推荐、摘要这些任务里权重高的文本被认为是与用户问题语义最贴近的内容,用在后续的rerank、filter 加权召回机制。
第三个改动是控制策略,我觉得是改的最成功的x
query
├──► 关键词命中 ➜ keyword_chunks
├──► FAISS 语义向量召回 ➜ faiss_chunks
└──► reranker 精排 ➜ reranked_chunks
├──► 合并 + 去重 + 加权排序
└──► 拼接 Prompt,控制 Token 长度
为每个 chunk 分配加权评分 score:
final_score = α * keyword_boost + β * (1 / faiss_distance) + γ * rerank_score
def score_chunks(keyword_chunks, reranked_chunks):
seen = set()
all_chunks = []
for chunk in keyword_chunks:
chunk_id = chunk['id']
if chunk_id not in seen:
chunk['final_score'] = 1.0
all_chunks.append(chunk)
seen.add(chunk_id)
for i, chunk in enumerate(reranked_chunks):
chunk_id = chunk['id']
if chunk_id not in seen:
chunk['final_score'] = 0.5 + 0.05 * (10 - i)
all_chunks.append(chunk)
seen.add(chunk_id)
return sorted(all_chunks, key=lambda c: c['final_score'], reverse=True)
Token Budget 控制
MAX_TOKEN_LIMIT = 3000
def trim_chunks_to_budget(chunks, tokenizer):
result = []
token_count = 0
for chunk in chunks:
tokens = len(tokenizer.encode(chunk['text']))
if token_count + tokens <= MAX_TOKEN_LIMIT:
result.append(chunk)
token_count += tokens
else:
break
return result
prompt
设定专家助手的角色和明确限制只使用给定文本作为信息来源,设置了“禁止幻觉”和“无法回答即返回固定句式”,加了编号引用系统让输出可追溯。
def build_prompt(retrieved_texts, user_question):
"""
Constructs a context-constrained prompt optimized for a RAG system focused on Byzantine history.
Parameters:
- retrieved_texts (list of str): Relevant textual passages retrieved from historical sources.
- user_question (str): The user's query related to Byzantine history.
Returns:
- str: A structured prompt that enforces evidence-based, context-aware answering with clear boundaries.
"""
context = "\n\n---\n\n".join(
[f"[{i+1}] {text}" for i, text in enumerate(retrieved_texts)]
)
prompt = f"""
You are a historical assistant with deep expertise in Byzantine history. Your task is to answer user questions **based strictly on the provided reference texts**.
Instructions:
- Use **only** the information contained in the reference texts below. Do **not** rely on external knowledge, prior assumptions, or general historical facts unless explicitly stated in the texts.
- You **must not hallucinate** or guess. If the answer is not clearly supported by the reference texts, respond exactly with:
"The answer is not available in the provided sources."
- When citing evidence, refer to the corresponding numbered source in square brackets (e.g., [1], [2]).
- You may synthesize information from **multiple references** to form a comprehensive answer.
- Be accurate, concise, and maintain academic tone.
Reference Texts:
{context}
User Question:
{user_question}
Answer:
"""
return prompt.strip()
实操
现在文件结构

运行结果:
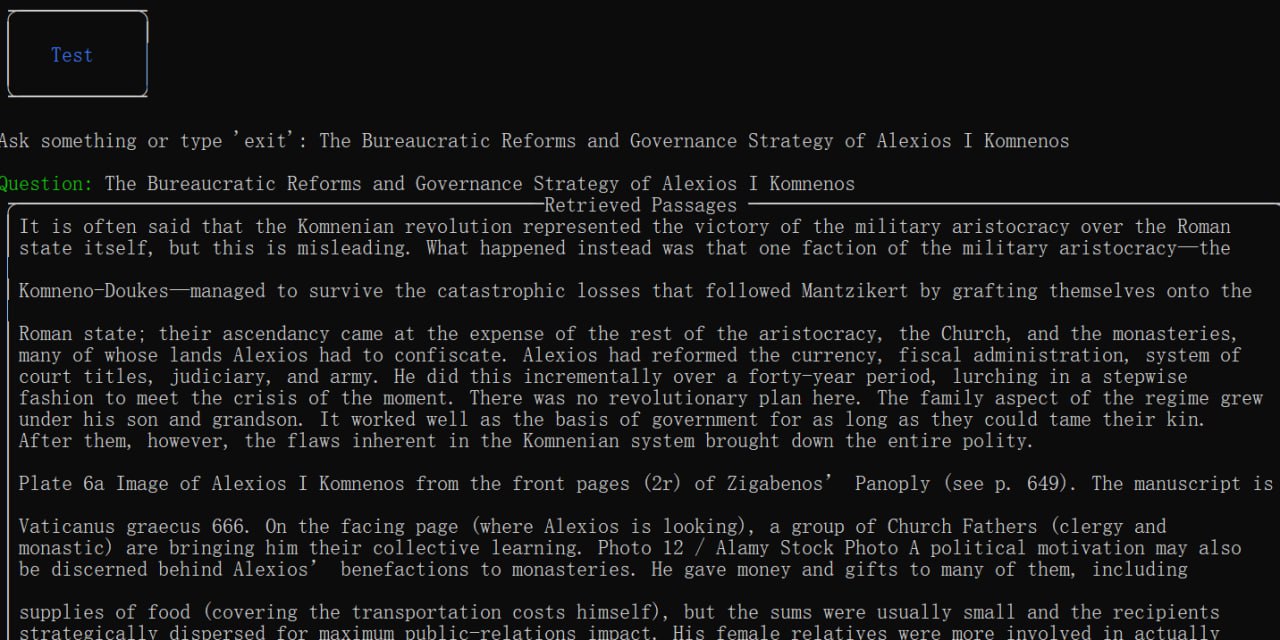
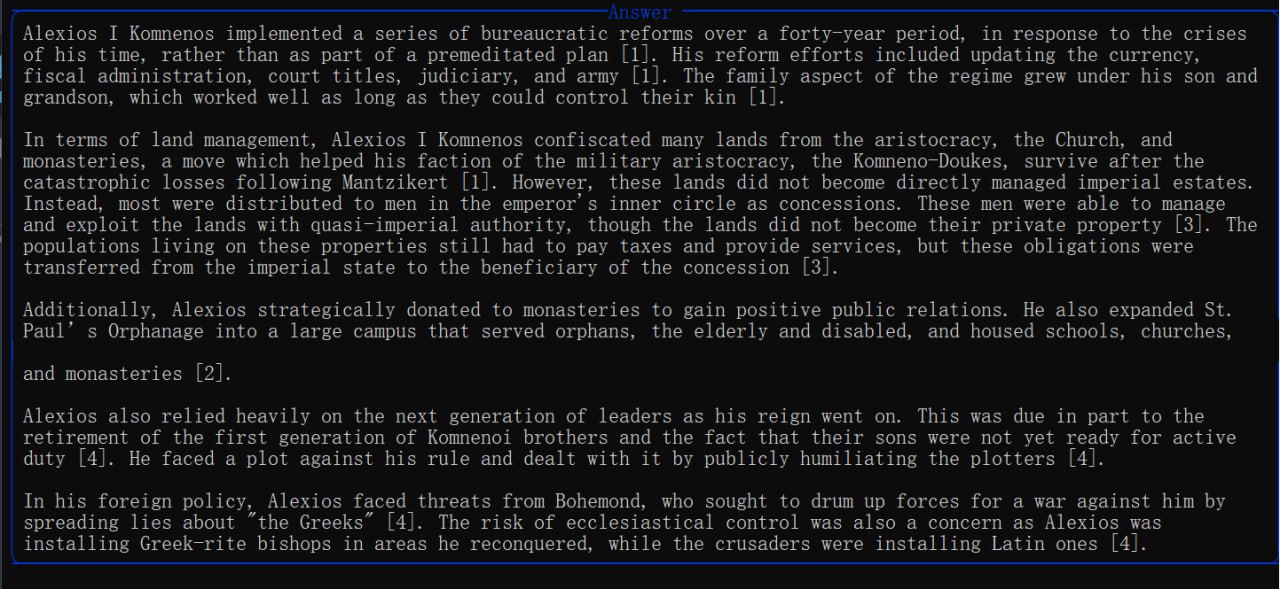
先返回了显示检索到的上下文片段,再展示大模型生成的回答&生成多个问题释义来用于语义扩展查询。