refer论文 Black-Box Based Limited Query Membership Inference Attack
MIA是一个推断某个特定样本有没有被用于训练目标模型的攻击方法,黑盒条件下的攻击者目标是通过与模型的有限交互,仅靠模型对输入的预测结果来判断该输入是否为训练数据中的一员。
“有限查询”是黑盒推理攻击的主要限制条件,攻击者既无法无限次地访问模型也无法获得模型的参数或架构信息,而白盒攻击,有限查询攻击更贴近现实中部署好的黑盒API接口。有限查询MIA的基本假设是模型对训练过的样本和未见过的样本响应存在的差异。例如模型可在训练样本上预测概率更极端和误差更小,在未见过的数据上就显得更犹豫和不稳定,攻击者可以利用这些行为差异设计统计分析工具、判别器模型、影子模型来进行推理。
Shadow Model是一种辅助性训练模型,用于模拟目标模型(Target Model)的决策边界与输出行为。在成员推理攻击(Membership Inference Attack, MIA)中,攻击者由于无法访问目标模型的内部结构与训练数据,便使用一组自己拥有的辅助数据集训练一个或多个影子模型,以逼近目标模型的输入输出分布。
这些影子模型被用于构造成员与非成员样本的行为分布对比特征,例如预测概率、logits分布、预测熵等。基于这些统计特征,攻击者可以训练一个攻击模型(Attack Model),以二分类形式判断某输入样本是否是影子模型的成员。由于影子模型的行为近似目标模型,该攻击模型可以泛化应用到目标模型,实现对实际样本的成员状态的推断。
如图
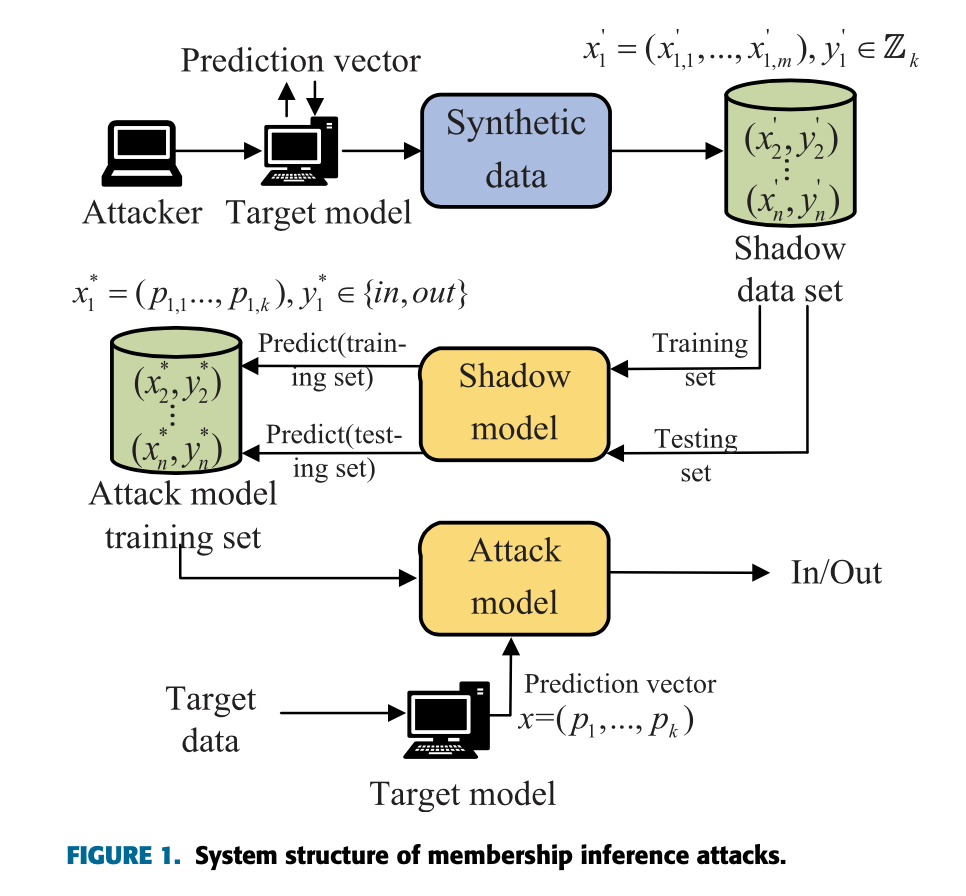
黑盒推理主要组成部分:目标模型(Target Model)影子模型(Shadow Model)攻击模型(Attack Model) 攻击者先通过查询目标模型收集数据,然后训练影子模型来模拟目标模型的行为,最后利用影子模型的已知成员信息训练攻击模型。
第一阶段是数据增强,使用条件生成CGAN对通过少量查询获得的数据进行扩充,构建了一个包含生成器G和判别器D的对抗系统,其中生成器接收100维的随机噪声向量和类别标签作为输入,输出与原始数据具有相似分布的合成数据。判别器则负责区分真实数据和生成数据,通过这种对抗训练机制,生成器逐步学会产生高质量的合成样本。
为了确保生成数据的有效性,作者将扩充后的数据集分为两部分:通过查询目标模型获得的概率值较高的数据被标记为类似训练集的数据(x_in_aug),而概率值较低的数据则被标记为非训练集数据(x_out_aug)。
第二阶段的影子模型训练是整个攻击流程的关键环节,和传统方法不一样的点在于这个研究使用单一的深度神经网络作为影子模型,而不是非针对每个类别训练多个模型。模型采用ResNet架构的卷积神经网络,能处理32×32像素的输入图像,训练过程中设计了一个包含两个约束条件的损失函数:类别约束确保影子模型能够正确分类输入数据,而距离约束则通过最小化影子模型输出与目标模型输出之间的均方误差来引导影子模型学习目标模型的预测行为。
补充
这里的影子模型使用了一个复合损失函数,包含两个约束: L = CE(S(x_in_aug), y_in_aug) + a × d(S(x_in_aug), T(x_in_aug))
其中第一部分是类别约束:CE(S(x_in_aug), y_in_aug) * 是交叉熵笋丝,是为了确保影子模型对输入数据做出正确判断,第二部分是距离约束:d(S(x_in_aug), T(x_in_aug)) * 是距离约束,用于引导影子模型S模仿目标模型T的预测行为。
权重参数a是控制距离损失的权重,在实验中设置为0.2。
论文里面的距离约束采用均方误差(MSE)来衡量:d(S(x_in_aug), T(x_in_aug)) = MSE(S(x_in_aug), T(x_in_aug))
训练数据处理是使用增强后的数据集* x_in_aug作为影子模型的训练集,再使用 x_out_aug*作为影子模型的测试集。
第三阶段的攻击模型训练将成员推理问题转化为二分类任务,利用影子模型在训练数据和测试数据上的预测输出,结合相应的成员标签(’in’ ‘out’),构建攻击模型的训练数据集。针对不同的数据类别,他们分别训练独立的攻击模型,当需要判断某个数据样本的成员身份时,系统会根据该样本的类别选择相应的攻击模型进行预测。
这个结果是和Shokri提出的经典成员推理攻击方法进行对比的,找了原文也读了一遍,大致可以总结为这是第一个针对机器学习即服务的成员推理攻击方法,基于一个关键观察:机器学习模型在训练集数据和非训练集数据上的表现存在差异,成员推理攻击正是利用这种差异。使用的是真实/合成数据手工构建多个影子模型,数据生成策略选的是模型合成、统计估计、带噪真实数据,这个非常依赖大量查询。攻击模型训练部分为每个类别训练一个独立的攻击模型,输入是模型输出 + 标签。
对比第一篇,影子模型的生成是GAN/CGAN 生成增强数据构建单个神经网络影子模型,数据生成的环节使用的是GAN自动扩增样本,显著减少了查询次数。攻击模型训练环节合成in/out标签的数据集,训练的是一个或多个标准二分类器。
Shokri的经典方法的问题在于查询数量需求大,因为需要大量查询目标模型来获取足够的训练数据,以及在目标模型结构未知的黑盒情况下,难以获得高度适应的影子模型。
我接下来想做的方向是针对文本RAG系统的成员推理攻击,目标是给定一个输入query和系统输出的回答,判断某段特定文本是否属于训练数据或检索库,同样是黑盒&拥有候选段落集&可模拟或访问部分背景语料。
思路还是从最终生成回答出发,逆推是否使用了目标段落(候选段 pᵢ)作为基础内容,准备成员/非成员段落集合,将这些query提交给RAG系统获取生成回答。通过文本BLEU或者语BERTScore衡量生成回答与候选段落之间的匹配度。在大规模验证中还可以扩展为训练一个攻击模型,匹配指标和其他辅助特征作为输入,以成员/非成员为标签,训练一个二分类器对未知段落进行判断。 最近了解到pluggable RAG system,是一个自由替换组件并独立控制输入输出的模块化文档检索的rag,特点是Retriever 与 Generator 是解耦的,可以选择不同的检索器也可以自由搭配不同生成器,还可以手动指定一组检索结果传入生成器,而不是自动调用 retriever。
上述可以做对抗性消融攻击,就是只移除或替换某一个候选段落然后观察生成输出变化。实现路径我考虑的是在有控制权限的平台上输入同一个query,在两种情境下生成回答,第一个是让成员段落被检索并参与生成,第二个是二是手动从候选集合中移除,来对比两种情境下的生成回答内容,评估差异。