
传统策略梯度方法是直接最大化策略的期望收益,但更新步长过大会策略跳太远让性能反而下降,类似PPO的TRPO是通过约束策略更新的KL散度,实现了信赖域更新,缺点是但算法复杂和计算开销大。PPO意在设计一个简单高效的目标函数,实现类似TRPO的保守更新效果。
PPO的基本思路是限制策略更新的幅度,防止新策略与旧策略差距太大,引入剪切clipping机制再确保更新不会偏离太远,同时再利用采样数据进行多次优化。clipping这个机制是它和TRPO的最大区别,因为在强化学习的策略梯度优化中,核心问题是如何更新策略参数θ使策略性能提升和稳定。

πθ:当前策略,参数为θ πθold:旧策略,参数为πθold At:优势函数Advantage,当前动作相比平均策略的优越程度
策略比率,衡量新旧策略在当前动作上的概率比 这里ϵ是一个小常数,限制策略比率的变化范围,clip(⋅) 操作将rt(θ) 限制在[1−ϵ,1+ϵ] 区间。 这个目标确保当rt(θ) 远离1时目标函数不再增大来抑制过度更新。
训练流程:数据采样→优势函数估计→构造剪切目标函数→多轮小批量优化→策略参数更新→重复迭代
剪切机制
限制策略变化幅度,保证训练稳定,剪切限制了策略概率比率在 [1−ϵ,1+ϵ] 之间,避免策略参数大幅度改变,保持新旧策略相似。当 rt(θ) 超出限制范围的时候目标函数的梯度不会继续增加,从而防止过度优化导致的策略性能下降。PPO剪切机制通过对策略比率做硬剪切来隐式实现像TRPO相似信赖域,同时使梯度不会因极端采样动作产生异常大来减少训练中的震荡。
initialize policy parameters θ and value function parameters φ
θ_old ← θ
for iteration in range(N_iterations):
trajectories = collect_trajectories(π_θ_old)
for t in trajectories:
compute advantage A_t using GAE
compute value target for critic
for epoch in range(K):
for minibatch in trajectories:
compute r_t = π_θ(a_t|s_t) / π_θ_old(a_t|s_t)
compute clipped surrogate loss:
L_clip = min(r_t * A_t, clip(r_t, 1 - ε, 1 + ε) * A_t)
compute value loss: L_v = (V_φ(s_t) - V_target)^2
compute entropy loss: L_H = -entropy[π_θ]
total_loss = -L_clip + c1 * L_v + c2 * L_H
update θ, φ using gradient descent
θ_old ← θ
采用的是双网络结构策略网络Actor与价值网络Critic,策略网络 π_θ 接收状态作为输入,输出每个动作的概率分布,而网络 V_φ 用于估计当前状态的状态值作训练中优势函数的计算依据。在每一轮更新中,当前策略π_θ_old会被用于与环境进行完整的交互,这种on-policy特性使PPO更加稳定从而避免了旧策略对当前策略训练的干扰。
for t in trajectories:
compute advantage A_t using GAE
compute value target for critic
优势值 A_t衡量某动作在当前策略下相对于基准状态值的优劣用的GAE 进行估计,GAE 在时间差分的基础上引入衰减系数 λ,通过加权累积回报控制偏差与方差之间的权衡升训练稳定性。
for epoch in range(K):
for minibatch in trajectories:
compute r_t = π_θ(a_t|s_t) / π_θ_old(a_t|s_t)
compute clipped surrogate loss:
L_clip = min(r_t * A_t, clip(r_t, 1 - ε, 1 + ε) * A_t)
ppo关键就在于构造剪切式surrogate objective,策略变化过大时clip函数将策略概率比 r_t 限制在 1 ± ε 范围内保证更新不会偏离旧策略过远,使用 min 函数控制梯度方向使优化仅在安全范围内更新策略。
除来策略目标外,还需要对值函数回归损失 L_v 与策略熵 L_H 加权组合形成总损失函数,值函数回归确保状态价值逼近真实回报,熵项鼓励策略保持探索性,最终使用总损失对 θ 和 φ 同步进行梯度更新,在每轮训练结束后用新参数更新旧策略。
在OpenAI的多个强化学习系统和InstructGPT中,都是使用的PPO作为核心训练策略,看了一些文章找到了为什么选择的理由。因为作为高效稳定的策略优化算法,PPO解决了之前训练不稳定问题,在复杂开发项目里面需要处理复杂的连续决策环境,这些场景中策略网络输出维度高、决策序列长,并且策略必须持续改进,但不能过度偏离当前策略,否则可能性能下降,剪切策略更新机制,使得训练过程中:每次更新都不过猛、允许在每一批样本上迭代多次,大幅提升样本效率、大规模并行训练中表现非常稳定且易于调参。
PPO也是RLHF的关键组件,在 OpenAI的自然语言模型训练中PPO被用于将人类反馈作为强化学习信号,RLHF的核心步骤是使用人类评分数据训练Reward Model-使用 PPO使语言模型在偏好一致的方向上优化-每轮输出一个句子奖励模型对其评分-作为 PPO 的外部回报信号。PPO在这里用于优化语言模型的输出策略使与人类指令对齐。相比其他策略优化方法,PPO能处理巨大模型输出的概率分布和易于在大模型中实现梯度反向传播。
RLHF伪代码
# 初始化模型、奖励模型、参考模型
initialize policy_model π_θ (e.g., GPT)
initialize reference_model π_ref = copy of π_θ
initialize reward_model R_φ (trained on human preference pairs)
# 收集人类反馈用于训练 reward model(已完成)
# 此阶段略:train_reward_model_on_human_preferences()
for iteration in range(N_updates):
# Step 1: 从当前策略模型 π_θ 生成文本样本
prompts = sample_prompts_from_dataset(batch_size)
responses = [ π_θ.generate(prompt) for prompt in prompts ]
# Step 2: 奖励模型评估输出,得到回报信号
rewards = [ R_φ(prompt, response) for (prompt, response) in zip(prompts, responses) ]
# Step 3: 计算旧策略 π_ref 的 log-probs,用于构造 r_t
logprobs_old = [ π_ref.log_prob(prompt, response) for (prompt, response) in zip(prompts, responses) ]
# Step 4: 构建 advantage 和返回值(可选 GAE)
values = policy_model.value_function(prompt, response) # optional if using critic
advantages = compute_advantages(rewards, values) # often just reward - baseline
# Step 5: 使用 PPO 构造损失并进行优化
for epoch in range(K_epochs):
minibatches = create_minibatches(prompts, responses, rewards, advantages, logprobs_old)
for minibatch in minibatches:
# 计算新策略概率比 r_t = exp(logπ_θ - logπ_old)
logprobs = policy_model.log_prob(minibatch.prompts, minibatch.responses)
r_t = exp(logprobs - minibatch.logprobs_old)
# PPO clipped loss
unclipped = r_t * minibatch.advantages
clipped = clip(r_t, 1 - ε, 1 + ε) * minibatch.advantages
loss_policy = -mean(min(unclipped, clipped))
# Value loss & entropy(可选)
values = policy_model.value_function(minibatch.prompts, minibatch.responses)
loss_value = MSE(values, minibatch.rewards)
entropy = compute_entropy(logprobs)
loss_total = loss_policy + c1 * loss_value - c2 * entropy
# 参数更新
optimizer.zero_grad()
loss_total.backward()
optimizer.step()
| 阶段 | 描述 |
|---|---|
| Step 1 | 策略模型 π_θ 生成回复(基于 prompt),这是 RLHF 中“行为采样”过程 |
| Step 2 | 使用奖励模型 R_φ 对回复评分,作为外部回报信号 |
| Step 3 | 使用旧策略 log-prob 构建 r_t,确保策略更新基于稳定参考策略 |
| Step 4 | 计算优势函数(可用 baseline 或 GAE)构建 PPO 的训练信号 |
| Step 5 | 使用 PPO 的 clipped surrogate objective 更新策略参数,防止策略崩溃 |
colab测试代码
# -*- coding: utf-8 -*-
"""Untitled8.ipynb
Automatically generated by Colab.
Original file is located at
https://colab.research.google.com/drive/1t2uqr1HWKC1jHc6HLeGwNYmQa-i2IASb
"""
!pip install gymnasium[classic-control] torch matplotlib --quiet
import gymnasium as gym
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
import matplotlib.pyplot as plt
from torch.distributions.categorical import Categorical
from tqdm.notebook import trange
from matplotlib import animation
from IPython.display import HTML, display
class ActorCritic(nn.Module):
def __init__(self, obs_dim, act_dim):
super().__init__()
self.shared = nn.Sequential(
nn.Linear(obs_dim, 64), nn.ReLU(),
nn.Linear(64, 64), nn.ReLU()
)
self.actor = nn.Linear(64, act_dim)
self.critic = nn.Linear(64, 1)
def forward(self, obs):
x = self.shared(obs)
return self.actor(x), self.critic(x)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
env = gym.make("CartPole-v1")
obs_dim = env.observation_space.shape[0]
act_dim = env.action_space.n
net = ActorCritic(obs_dim, act_dim).to(device)
optimizer = optim.Adam(net.parameters(), lr=1e-4)
def compute_gae(rewards, values, dones, gamma=0.99, lam=0.95):
adv = []
gae = 0
next_value = 0
for t in reversed(range(len(rewards))):
delta = rewards[t] + gamma * next_value * (1 - dones[t]) - values[t]
gae = delta + gamma * lam * (1 - dones[t]) * gae
adv.insert(0, gae)
next_value = values[t]
return adv
num_episodes = 2000
rewards_history = []
clip_eps = 0.1
entropy_coef = 0.02
value_coef = 0.5
target_kl = 0.02
for episode in trange(num_episodes):
obs, _ = env.reset()
done = False
obs_list, act_list, logp_list, rew_list, val_list, done_list = [], [], [], [], [], []
while not done:
obs_tensor = torch.tensor(obs, dtype=torch.float32).unsqueeze(0).to(device)
logits, value = net(obs_tensor)
probs = Categorical(logits=logits)
action = probs.sample()
log_prob = probs.log_prob(action)
next_obs, reward, terminated, truncated, _ = env.step(action.item())
done = terminated or truncated
obs_list.append(obs)
act_list.append(action.item())
logp_list.append(log_prob.item())
rew_list.append(reward)
val_list.append(value.item())
done_list.append(done)
obs = next_obs
obs_tensor = torch.tensor(obs_list, dtype=torch.float32).to(device)
act_tensor = torch.tensor(act_list).to(device)
logp_tensor = torch.tensor(logp_list).to(device)
val_tensor = torch.tensor(val_list).to(device)
rew_tensor = torch.tensor(rew_list, dtype=torch.float32).to(device)
done_tensor = torch.tensor(done_list, dtype=torch.float32).to(device)
adv_tensor = torch.tensor(compute_gae(rew_list, val_list, done_list), dtype=torch.float32).to(device)
returns_tensor = adv_tensor + val_tensor
adv_tensor = (adv_tensor - adv_tensor.mean()) / (adv_tensor.std() + 1e-8)
for _ in range(5):
logits, values = net(obs_tensor)
probs = Categorical(logits=logits)
new_logp = probs.log_prob(act_tensor)
ratio = (new_logp - logp_tensor).exp()
approx_kl = (logp_tensor - new_logp).mean().item()
if approx_kl > 1.5 * target_kl:
print(f"Early stopping at episode {episode}, KL = {approx_kl:.4f}")
break
surr1 = ratio * adv_tensor
surr2 = torch.clamp(ratio, 1 - clip_eps, 1 + clip_eps) * adv_tensor
policy_loss = -torch.min(surr1, surr2).mean()
value_loss = ((returns_tensor - values.squeeze()) ** 2).mean()
entropy = probs.entropy().mean()
loss = policy_loss + value_coef * value_loss - entropy_coef * entropy
optimizer.zero_grad()
loss.backward()
optimizer.step()
rewards_history.append(sum(rew_list))
plt.figure(figsize=(10, 5))
plt.plot(rewards_history, label="Episode reward")
plt.xlabel("Episode")
plt.ylabel("Total Reward")
plt.title("PPO with Entropy Bonus & KL Early Stopping")
plt.grid(True)
plt.legend()
plt.show()
def render_agent_as_gif(net, env, max_frames=500):
frames = []
obs, _ = env.reset()
done = False
for _ in range(max_frames):
frame = env.render()
frames.append(frame)
obs_tensor = torch.tensor(obs, dtype=torch.float32).unsqueeze(0).to(device)
with torch.no_grad():
logits, _ = net(obs_tensor)
probs = Categorical(logits=logits)
action = probs.sample().item()
obs, reward, terminated, truncated, _ = env.step(action)
if terminated or truncated:
break
env.close()
fig = plt.figure(figsize=(frames[0].shape[1] / 72, frames[0].shape[0] / 72), dpi=72)
plt.axis("off")
im = plt.imshow(frames[0])
def update(frame):
im.set_array(frame)
return [im]
ani = animation.FuncAnimation(fig, update, frames=frames, interval=30)
html = ani.to_jshtml()
plt.close()
display(HTML(html))
render_env = gym.make("CartPole-v1", render_mode="rgb_array")
render_agent_as_gif(net, render_env)
| 使用的是共享特征网络的Actor-Critic架构,共享网络(self.shared)是两层 64 维全连接层,ReLU激活来用于提取状态特征,Actor 输出头(self.actor)生成 logits用于构造策略 π(a | s),Critic输出头(self.critic)是输出状态价值估计 V(s),用于后续优势函数计算。 |
while not done:
obs_tensor = torch.tensor(obs, dtype=torch.float32).unsqueeze(0).to(device)
logits, value = net(obs_tensor)
probs = Categorical(logits=logits)
action = probs.sample()
log_prob = probs.log_prob(action)
next_obs, reward, terminated, truncated, _ = env.step(action.item())
done = terminated or truncated
obs_list.append(obs)
act_list.append(action.item())
logp_list.append(log_prob.item())
rew_list.append(reward)
val_list.append(value.item())
done_list.append(done)
obs = next_obs
⬆️,在每一回合episode,智能体使用当前策略和价值函数在环境中完整地执行一条轨迹并收集用于训练的数据。
逻辑流程是obs → net → actor & critic:获取动作分布 π(a → 从 Categorical(logits) 中随机采样一个离散动作 → env.step(action.item()) 与环境交互,获得下一状态、奖励、终止信息 → 把当前时间步的信息全部保存在列表中
def compute_gae(rewards, values, dones, gamma=0.99, lam=0.95):
adv = []
gae = 0
next_value = 0
for t in reversed(range(len(rewards))):
delta = rewards[t] + gamma * next_value * (1 - dones[t]) - values[t]
gae = delta + gamma * lam * (1 - dones[t]) * gae
adv.insert(0, gae)
next_value = values[t]
return adv
⬆️,delta计算公式δt =rt +γV(st+1 )−V(st ),表示一步TD误差,也就是当前状态的价值和实际获得奖励加下一个状态价值之间的差距。GAE公式递推A^t =δt +γλA^t+1,指数加权的多步TD 误差,可以在偏差与方差之间调节,接下来如果episode终止那么后续的估值应为0。返回的是优势值序列adv来策略梯度的目标函数。
for _ in range(5):
logits, values = net(obs_tensor)
probs = Categorical(logits=logits)
new_logp = probs.log_prob(act_tensor)
ratio = (new_logp - logp_tensor).exp()
在PPO算法中我们希望优化如下目标函数:L(θ)=Et [min(rt (θ)A^t ,clip(rt (θ),1−ϵ,1+ϵ)A^t )]。
⬆️logp_tensor 是旧策略对动作的对数概率 new_logp 是当前策略对相同动作的对数概率 ratio 即为重要性采样比 rt (θ)
surr1 = ratio * adv_tensor
surr2 = torch.clamp(ratio, 1 - clip_eps, 1 + clip_eps) * adv_tensor
policy_loss = -torch.min(surr1, surr2).mean()
⬆️,Clip损失实现,防止策略剧烈更新
| 项 | 含义 |
|---|---|
surr1 |
使用真实比率进行策略梯度更新 |
surr2 |
将比率裁剪到 1 - epsilon, 1 + epsilon 范围 |
min(...) |
对每一步都选择保守的目标,以避免剧烈更新 |
-mean |
PPO使用梯度下降,故取负号最小化损失 |
approx_kl = (logp_tensor - new_logp).mean().item()
if approx_kl > 1.5 * target_kl:
print(f"Early stopping at episode {episode}, KL = {approx_kl:.4f}")
break
⬆️,KL散度早停机制防止策略崩溃的。
| 参数 | 含义 |
|---|---|
target_kl |
用户设置的期望最大KL |
approx_kl |
当前更新中策略的实际KL散度 |
1.5 × target_kl |
提前终止的触发阈值 |
为什么需要早停?因为PPO本身没有约束KL距离,clip机制只是间接限制,如果 advantage 较大会导致 ratio 剧烈偏离,添加 KL early stopping 是一种额外的安全机制来用于增强PPO的稳定性与收敛性。
entropy = probs.entropy().mean()
loss = policy_loss + value_coef * value_loss - entropy_coef * entropy
熵奖励项是鼓励策略保持“随机性”与探索,在早期训练阶段,如果策略太早变得确定会导致陷入局部最优。
| 项 | 含义 |
|---|---|
probs.entropy() |
当前策略分布的信息熵,越大代表越“随机” |
entropy_coef |
熵项的权重(代码中为 0.02) |
-entropy |
熵越大,总 loss 越小,即鼓励探索 |
value_loss |
Critic 的 MSE 回归损失 |
policy_loss |
PPO策略主损失项 |
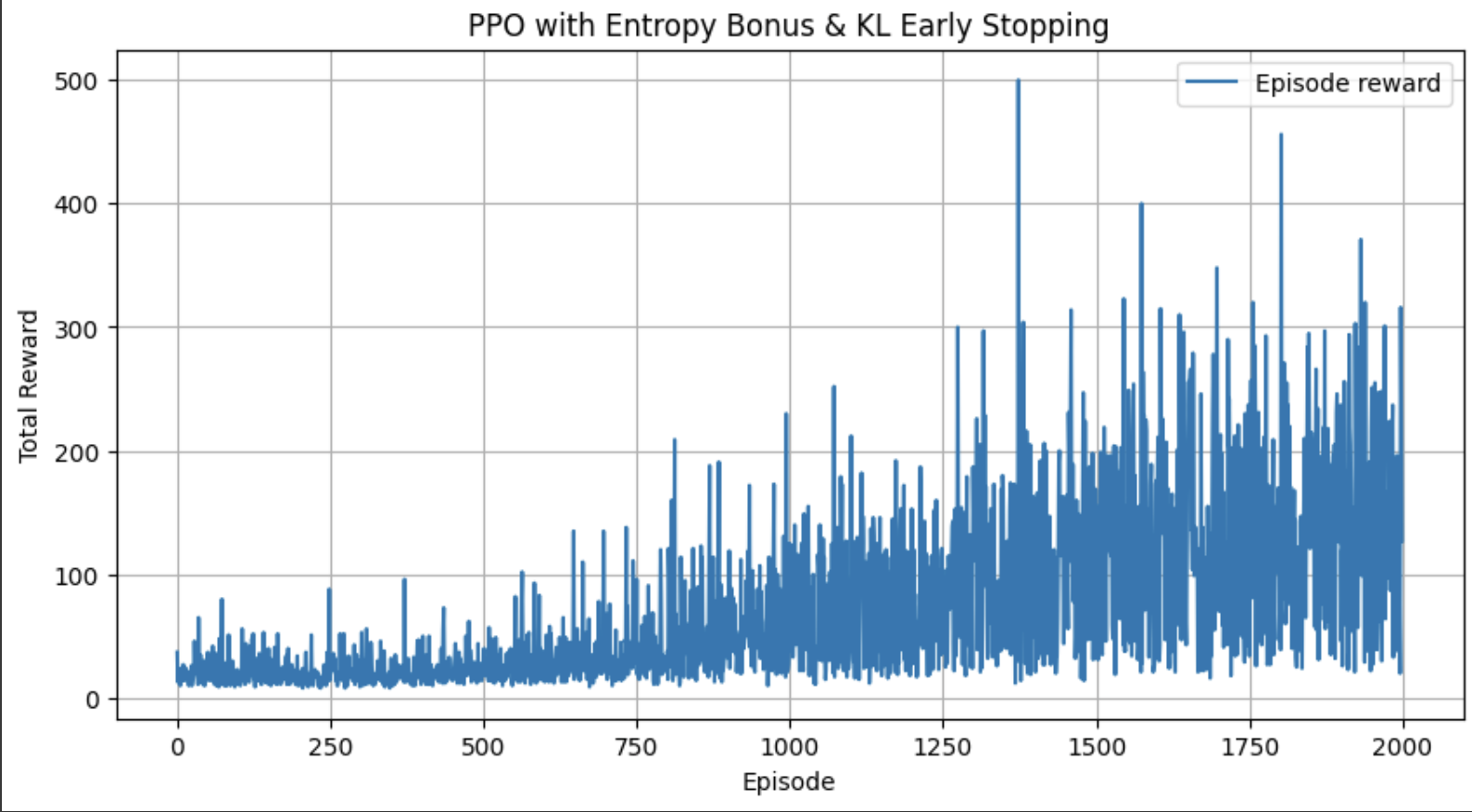
可视化部分我最后绘制了训练奖励曲线,横轴是训练回合数(episode),纵轴是每一回合累计获得的总奖励(sum(rew_list)),绘制的是智能体的表现变化曲线。以及生成智能体执行过程的 GIF,使用训练好的策略执行一次完整的 episode将每一帧图像存为序列转为 HTML 动画。
为什么写这个作为教学性友好代码?因为ActorCritic 中显式分离 actor 和 critic,采样 → 优化 → logging清晰,并且核心机制易观察。使用的环境是经典的CartPole-v1,状态维度低(4维),动作空间离散(2维),奖励结构简单清晰(每步+1)。
但是现在每回合只用一批数据更新,并且当前的target_kl是固定的,没有多回合采样&没有使用 Mask处理不同长度轨迹。