由大型语言模型(LLMs)驱动的深度研究代理正在迅速发展;然而,在使用通用的测试时扩展算法生成复杂的长篇研究报告时,它们的性能常常会停滞不前。受人类研究迭代特性的启发——该过程涉及搜索、推理和修订的循环——我们提出了测试时扩散深度研究员(TTD-DR)。
这个新颖的框架将研究报告的生成过程概念化为一个扩散过程。TTD-DR通过一份初步草稿来启动此过程,这份草稿是一个可更新的骨架,作为不断演进的基础来指导研究方向。随后,该草稿通过一个“去噪”过程被反复精炼,该过程由一个检索机制在每一步动态地引入外部信息来提供支持。
核心过程通过应用于代理工作流每个组件的自进化算法得到进一步增强,确保为扩散过程生成高质量的上下文。这种以草稿为中心的设计使报告撰写过程更加及时和连贯,同时减少了在迭代搜索过程中的信息损失。我们证明了我们的TTD-DR在需要密集搜索和多跳推理的广泛基准测试中取得了最先进的结果,显著优于现有的深度研究代理。
Deep research agents, powered by Large Language Models (LLMs), are rapidly advancing; yet, their performance often plateaus when generating complex, long-form research reports using generic test-time scaling algorithms. Drawing inspiration from the iterative nature of human research, which involves cycles of searching, reasoning, and revision, we propose the Test-Time Diffusion Deep Researcher (TTD-DR). This novel framework conceptualizes research report generation as a diffusion process. TTD-DR initiates this process with a preliminary draft, an updatable skeleton that serves as an evolving foundation to guide the research direction. The draft is then iteratively refined through a “denoising” process, which is dynamically informed by a retrieval mechanism that incorporates external information at each step. The core process is further enhanced by a self-evolutionary algorithm applied to each component of the agentic workflow, ensuring the generation of high-quality context for the diffusion process. This draft-centric design makes the report writing process more timely and coherent while reducing information loss during the iterative search process. We demonstrate that our TTD-DR achieves state-of-the-art results on a wide array of benchmarks that require intensive search and multi-hop reasoning, significantly outperforming existing deep research agents.Deep research agents, powered by Large Language Models (LLMs), are rapidly advancing; yet, their performance often plateaus when generating complex, long-form research reports using generic test-time scaling algorithms. Drawing inspiration from the iterative nature of human research, which involves cycles of searching, reasoning, and revision, we propose the Test-Time Diffusion Deep Researcher (TTD-DR). This novel framework conceptualizes research report generation as a diffusion process. TTD-DR initiates this process with a preliminary draft, an updatable skeleton that serves as an evolving foundation to guide the research direction. The draft is then iteratively refined through a “denoising” process, which is dynamically informed by a retrieval mechanism that incorporates external information at each step. The core process is further enhanced by a self-evolutionary algorithm applied to each component of the agentic workflow, ensuring the generation of high-quality context for the diffusion process. This draft-centric design makes the report writing process more timely and coherent while reducing information loss during the iterative search process. We demonstrate that our TTD-DR achieves state-of-the-art results on a wide array of benchmarks that require intensive search and multi-hop reasoning, significantly outperforming existing deep research agents.
常用的四种llm技术
现有的LLM的深度研究代理在生成复杂的长篇报告的时候性能通常会停滞,瓶颈的根源在于它们全都严重依赖一套通用的的测试时扩展算法。
论文里面提到过现在常用的四种技术,我这里扩展一下:
Chain-of-Thought, CoT
思维链就是一种Prompting技术,引导大语言模型在给出最终答案之前先输出一步步的推理过程。在少样本学习场景下,提供给模型的不仅是问题和答案,而是问题-推理步骤-答案的完整sample,模型在学习这些示例后遇到新问题时会模仿这种格式。先生成自己的逻辑链,然后基于这个链条得出结论。Google PaLM和gpt34都用到了这个,但是思维链在长篇报告中是有局限性的,因为线性的思维链容易偏离主题,假设AI需要撰写一份关于全球半导体供应链风险及对策的20页深度报告。初始链条就为定义半导体供应链-分析其全球分布-识别地缘政治风险…….在执行第3步时,模型可能生成了非常详细的关于美国芯片法案的内容,但是由于思维链的线性特性它会继续深化这个子主题,在这个过程中,它可能忘记了报告的全局上下文,报告可能会在某个局部细节上过于深入导致结构失衡;以及思维链难以整合外部信息,线性的思维链很难优雅地处理这个新信息,它无法轻易地返回到之前的规划步骤,将这个新风险点整合进报告大纲。
Best-of-n Sampling
多样本抽样是一种提升输出质量的解码策略,它不满足于模型生成的第一个答案而是通过引入一定的随机性让模型对同一个输入Prompt生成多个不同的候选输出,然后通过一个外部的评判机制从这 n 个候选中选出最佳的一个作为最终结果。在长篇报告中的局限性一是计算成本高,二是启发式的选择标准可能导致信息丢失,一个奖励模型很可能会因为版本A的流畅性和完整性而给它最高分。然而,这个选择过程丢弃了版本B和C中的宝贵的洞见,我们理想的系统应该能将版本A的结构、版本B的深度数据和版本C的独特视角融合在一起,而Best-of-n机制做不到这一点,它只能三选一.
蒙特卡洛树搜索
MCTS是一种用于在庞大决策空间中进行智能搜索的启发式算法,通过构建一个搜索树来表示所有可能的决策路径,在文本生成中每个节点可以代表一个词一个句子或一个段落。算法通Simulation Evaluation Backpropagation和Expansion四个步骤来判断哪些生成路径更有前途然后投入更多计算资源进行探索。
但是写作过程的动态性难以被树状结构捕捉,因为人类写作是一个高度动态和迭代的过程,一个研究员可能会在写结论部分时,突然意识到引言部分的某个提法不够准确,于是立刻跳回去修改引言。或者他可能会同时起草方法论和结果两个章节来让它们相互印证,MCTS本质上仍是一种结构化的前瞻性的规划方法,很难模拟这种非线性的多任务并行的创作心流。
辩论机制和自修正循环
这两种方法都是通过引入批判性思维来提升内容质量。辩论机制是引入多个AI代理,让它们扮演不同角色针对同一个主题或论点进行辩论,通过相互诘难来暴露彼此的逻辑漏洞、事实错误或片面观点 。自修正循环谁让单个AI代理扮演两个角色。这些方法非常擅长进行局部优化,辩论和自修正通常在孤立的环境下进行,缺乏一个贯穿全文的中心草稿来引导。
核心思想方法论
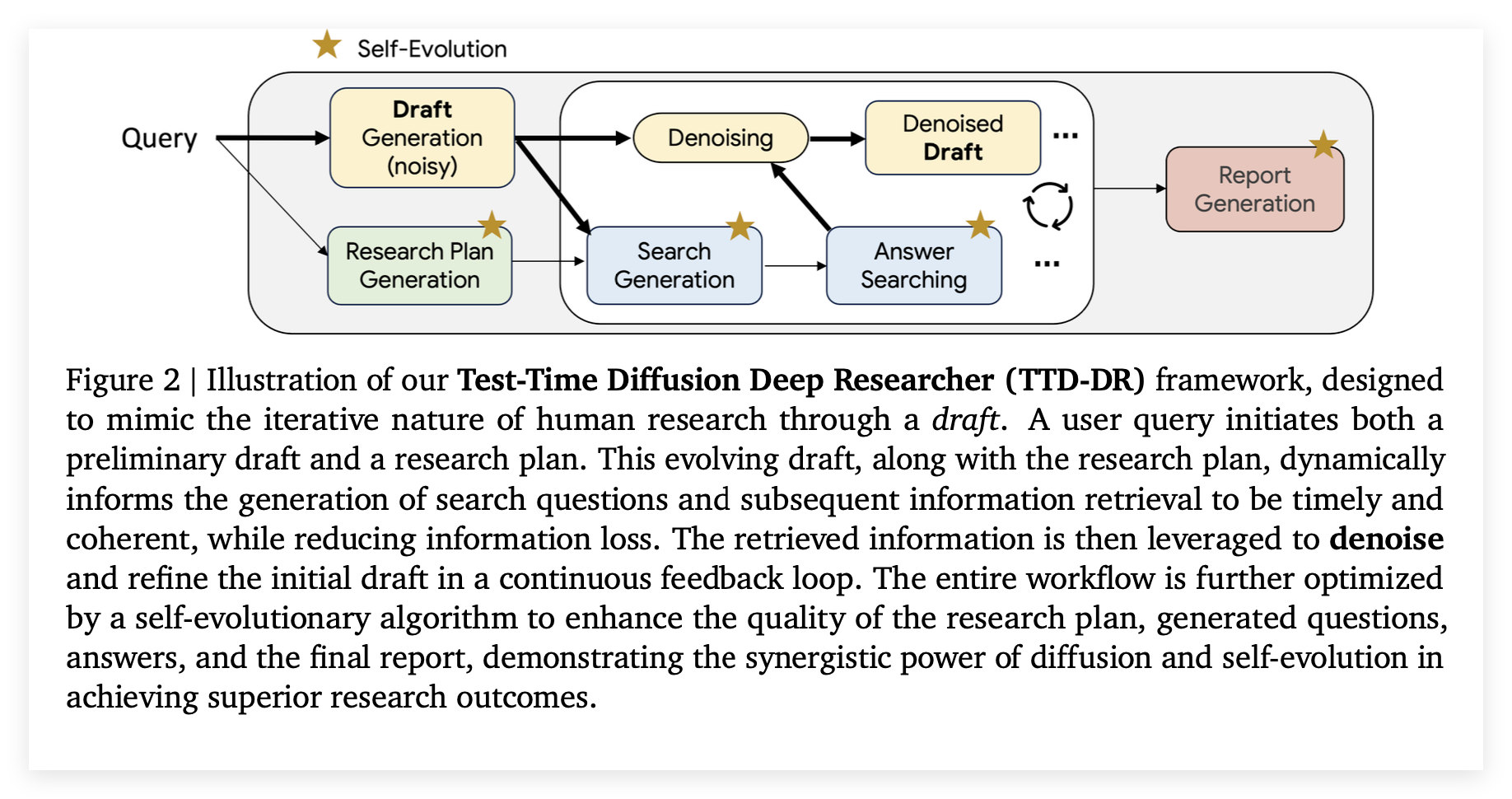
Test-Time Diffusion Deep Researcher, TTD-DR就是解决以上问题的一个新颖框架,思想源于对人类研究与写作认知过程的观察并与机器学习中的扩散模型进行了类比,整个方法论由一个核心思想和两大支撑机制构成并建立在一个模块化的骨干代理之上。
作者观察到人类撰写复杂报告的过程不是线性写完的,而是一个迭代和循环往复的流程,包含规划、起草、搜索和反复修改,这和扩散模型从一个带噪的初始状态通过逐步去噪最终生成高质量输出的采样过程惊人地相似,基于此TTD-DR框架将研究报告的生成过程概念化为一个扩散过程 (diffusion process) 。
整个流程始于一份初步草稿 ,这份草稿主要基于大语言模型LLM的内部知识生成因此被视为带噪的、不完整或不精确的起点。这份初稿随后会通过一个迭代的去噪过程被反复精炼,与图像去噪不同,这里的去噪指的是通过外部信息来修正报告中的不精确之处来填补缺失的信息以及验证现有内容 。整个过程的关键在于草稿是一个可更新的、不断演进的骨架,动态地引导着整个生成的方向。
这个机制就是TTD-DR框架的核心,它将整个报告的生成过程从一个线性的一次性任务,转变为一个动态的、循环演进的扩散过程,这个流程始于一个主要由大语言模型内部知识生成的初步草稿,把这个草稿被视为一个带噪的起点作为一个可更新的骨架。
论文里面提到了仅仅让模型在没有外部上下文的情况下自我修正输出,这样收敛速度慢而且效果不佳,对于需要外部知识的复杂研究查询更是如此,因此这个机制将去噪过程与外部信息检索紧密耦合,在每一个迭代循环中,当前版本的去噪后草稿会连同初始的研究计划一起被用来指导下游搜索问题生成模块的工作 。当答案搜索模块利用外部工具返回一个经过综合的答案后,这个新信息会被用来修正草稿 ,无论是增加缺失的细节还是验证和修正现有内容。这个草稿指导搜索、搜索精炼草稿的持续反馈循环确保了报告的撰写过程是及时且连贯的,还减少了在长序列迭代搜索中的信息丢失。
组件级优化
为了给宏观的扩散过程提供最高质量的养料,TTD-DR引入了组件级的自我进化算法,算法并非仅作用于最终报告而是可以应用于工作流中的任何一个独立组件,像是研究计划生成和搜索问题生成这些,目标是通过探索更多样的知识来提升每个信息单元的质量同时也减轻长代理轨迹中的信息损耗。
以搜索答案为例子:
- 系统统首先会调用一个LLM单元代理,通过调整temperature等参数,为同一个搜索查询生成多个内容多样化的候选答案。
- 每一个候选答案都会被一个作为裁判的llm进行评估,这个裁判不仅会根据有用性和全面性”等预设指标给出量化的适应度分数,还会生成具体的文本形式的批评意见。
- 基于上一步获得的分数和反馈,每个候选答案会进入一个修订环节在下一轮评估中获得更高的适应度分数。这个评估-反馈-修订的过程会形成一个循环工作流直至达到预设的停止条件。
- 在所有变体完成进化后会被输入到一个最终的合并环节,整合所有进化路径中的最佳信息生成一个单一的质量更高的最终输出 。
模块化的骨干深度研究代理
这个骨干代理为整个复杂的研究任务提供了基础的执行流程,它由三个主要阶段构成每个阶段都包含一个或多个作为基本单元的LLM代理、相应的工作流以及用于传递信息的代理状态
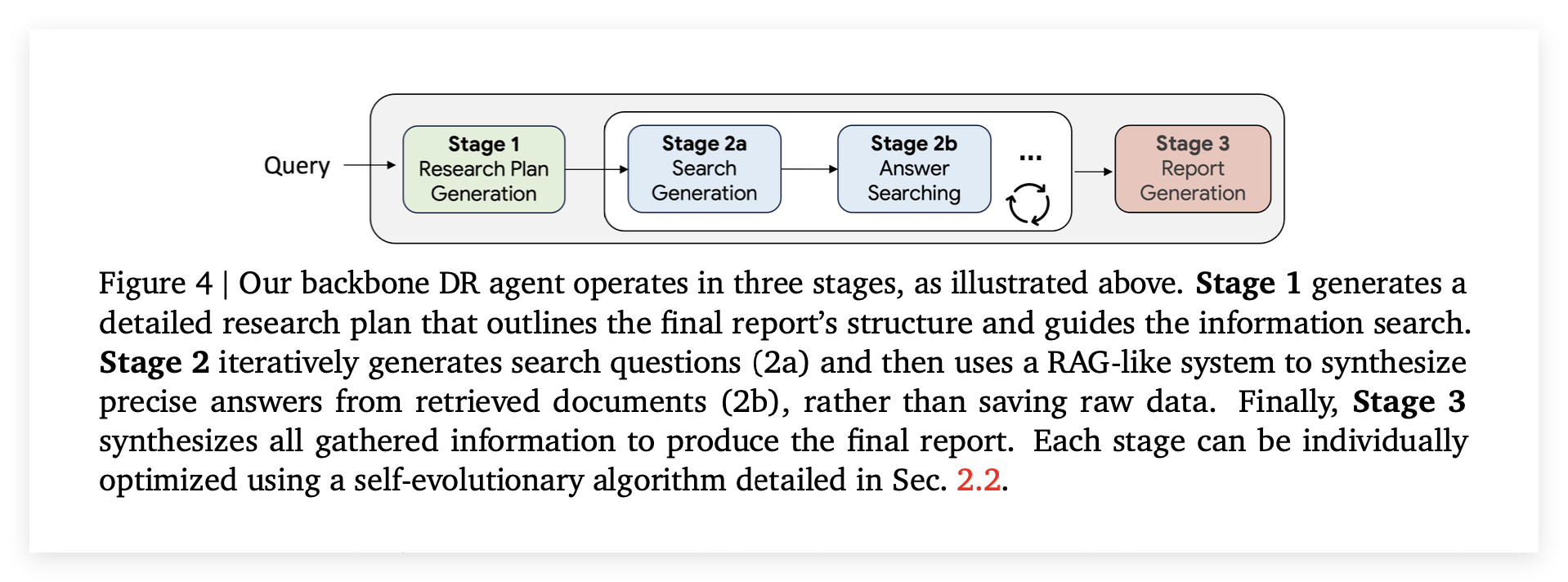
阶段一:研究计划生成
当代理接收到用户的查询后,一个专门的单元LLM代理会被激活,它的任务是生成一份结构化的研究计划,这份计划会列出最终报告所需涵盖的一系列关键领域或要点 ,它为最终报告勾勒出整体结构也是一开始的initial scaffold,研究计划一旦生成就会被保存在代理的状态中,并传递给下一阶段的子代理使用 。
阶段二:迭代式搜索与综合
这个被设计为一个循环工作流嵌套在其父级的顺序工作流之中,这个阶段包含两个协同工作的子代理:
搜索问题生成 (Search Question Generation):这个代理负责制定具体的搜索策略,会综合考量三个方面的信息:第一阶段生成的研究计划、用户的原始查询、以及所有之前搜索迭代中积累的上下文信息。通过整合这些信息,该代理能够构建出最符合当前研究需求、最能填补信息空白的搜索查询。
答案搜索 (Answer Searching):该代理负责执行搜索并整合信息,调用可用的外部信息源来查找相关的文档,与简单的信息抓取不同,这个代理的特点是它采用了一个类似RAG的系统 ,不直接保存原始的网页数据或文档而是将检索到的信息进行处理,综合成一个概括性的答案然后才保存下来 。循环机制是提问-回答的过程会持续循环直到研究计划中的所有要点都被充分覆盖,或者达到了预设的最大迭代次数,论文里面设定的是20次 。
阶段三:报告生成
这也是一个单元LLM代理,在第二阶段的迭代搜索循环结束后,这个最终代理会接收并整合所有先前积累的结构化信息,输入主要包括两部分,第一阶段生成的宏观研究计划和第二阶段收集到的一系列精确的问答对,通过对这些信息进行全面的综合与提炼最终生成一份内容全面的最终研究报告。论文还特别指出了骨干代理的每一个阶段都可以利用第2.2节中详细介绍的自我进化算法进行单独优化,进一步提升其输出质量 。
实验设置和评估
论文里面采取了三步走的策略:首先收集高质量的人类判断,然后用人类偏好来校准LLM-as-a-judge最后使用校准过的LLM裁判进行最终评估。有用性与全面性是评估长篇LLM响应时最常用的两个指标,有用性由四个标准定义 1满足用户意图 2易于理解3准确性4语言得当,全面性是定义为没有遗漏关键信息 。论文里面的并排质量比较也是一种被广泛采用的评估长篇LLM响应的方法,评估者被要求在报告A和报告B之间表达他们的偏好,偏好等级分为好很多 更好 稍好 大致相同。
LLM-as-a-judge 校准
对于没有标准答案的长篇响应使用LLM作为裁判也是一种可扩展的评估方法,但是以往的研究工作大多没有用人类评估员来专门校准LLM裁判所以自动评估结果的可靠性存疑 。
这里的校准过程是研究通过比较其DR代理与OpenAI Deep Research生成的200份报告用人类的评分来对齐和校准LLM裁判,经过校准和比对,最终选择Gemini-1.5-pro作为其LLM裁判模型。
论文选择了两大类任务来对代理进行基准测试:1) 需要生成长篇综合报告的复杂查询;2) 需要大量搜索和推理才能回答的多跳问题 。这两类任务都可能需要多达20个搜索步骤来完全解决用户查询。为了对标真实世界用例研究者整理了一套包含205个查询的授权数据集,这些查询要求进行深度研究以创建有用且全面的报告 。如图所示该数据集覆盖了技术、生物医学、社会科学等多个行业领域 。
核心结果与分析
论文的核心结果在表1中展示,数据显示TTD-DR在所有基准测试中均取得了持续优越的成绩 。
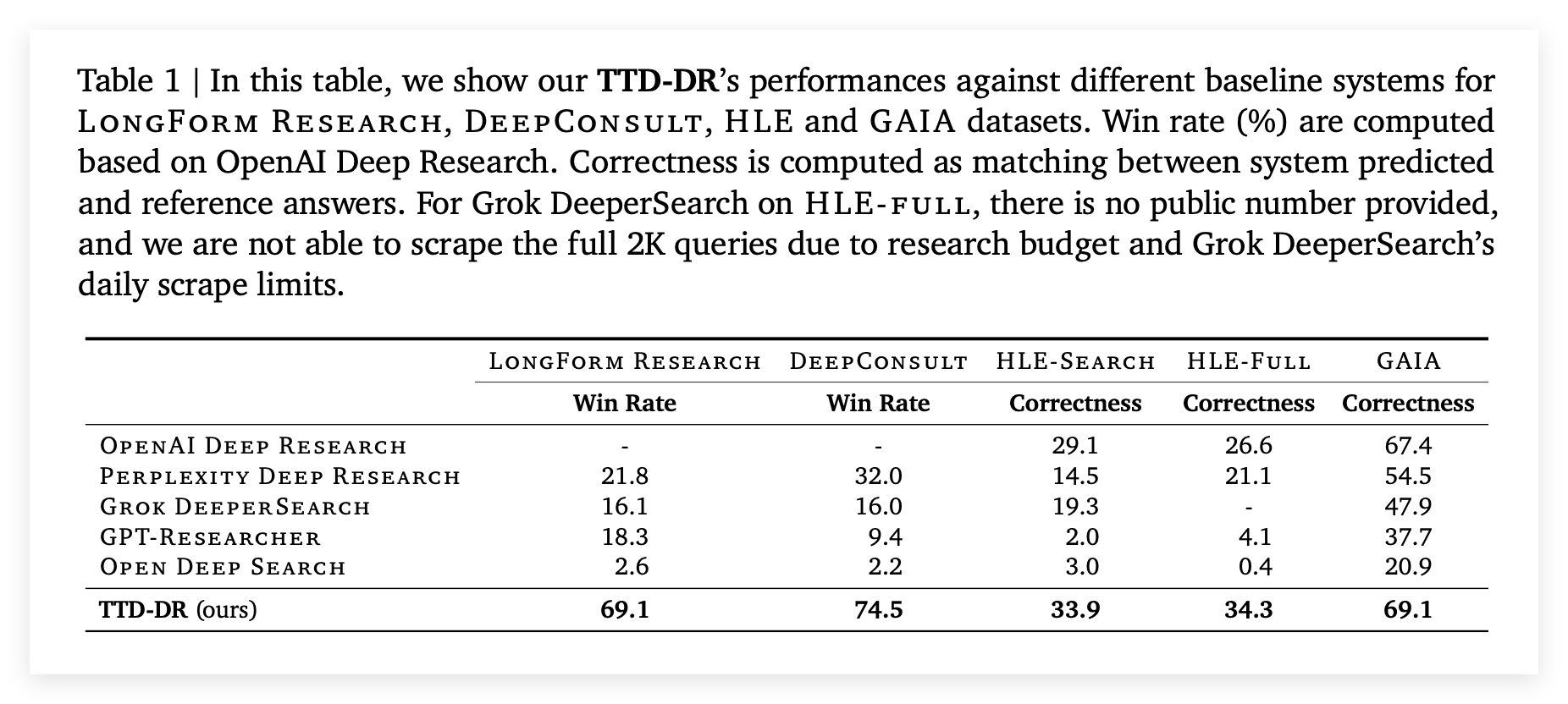
与业界领先的OPENAI DEEP RESEARCH相比,TTD-DR在LONGFORM RESEARCH和DEEPCONSULT这两个长篇报告生成任务上,分别取得了69.1%和74.5%的并排比较胜率 。在HLE-SEARCH、HLE-FULL和GAIA这三个需要大量研究的短答案数据集中,TTD-DR的正确率也分别比OPENAI DEEP RESEARCH高出4.8%、7.7%和1.7% 。
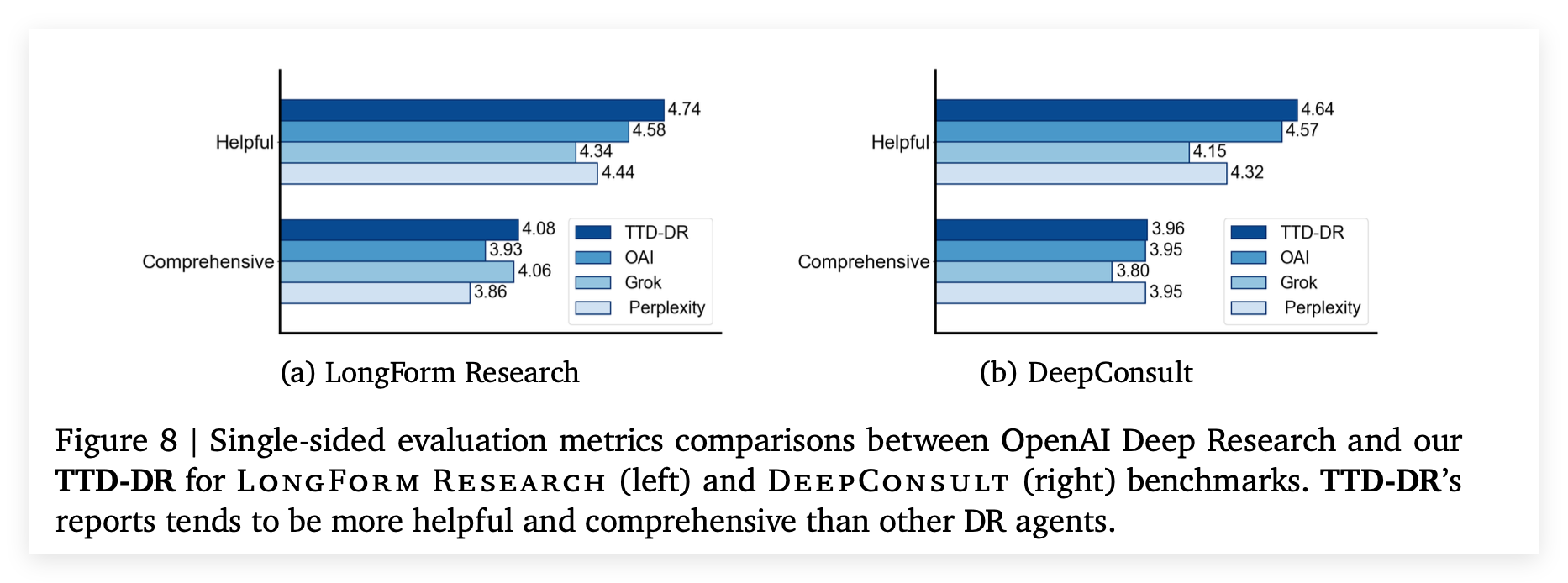
单项指标的评估分数显示TTD-DR在有用性和全面性这两项指标上也超越了包括OPENAI DEEP RESEARCH在内的其他代理
消融研究
表2中的消融研究展示了TTD-DR框架中每个组件的贡献。
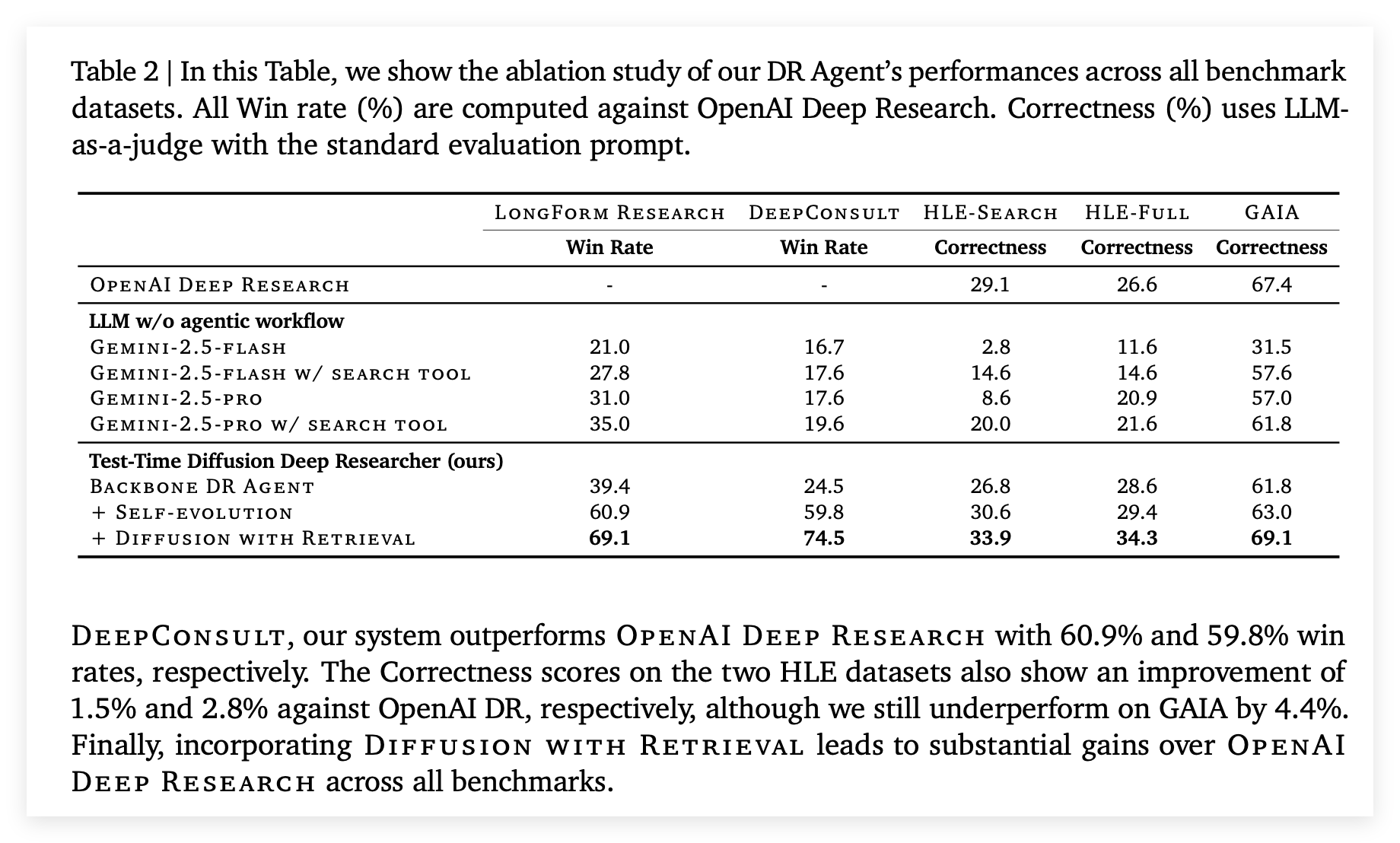
基础LLM的局限是即使是像GEMINI-2.5-PRO这样强大的LLM在没有搜索工具的情况下,在HLE-SEARCH这种搜索密集型数据集上的表现也十分糟糕,配备了简单的搜索工具后性能虽有提升但仍远低于专门的研究代理 。基础的骨干DR代理比简单的LLM+搜索有显著提升,但仍不及OPENAI DEEP RESEARCH 。Self-Evolution的贡献是在骨干代理的基础上增加自我进化算法后,系统在长篇报告任务上的胜率大幅提升至60.9%和59.8%已经超越了OPENAI DEEP RESEARCH 。Denoising with Retrieval起到了决定性作用,整合带检索的去噪机制,系统性能在所有基准上都取得了巨大的提升达到了最终的SOTA水平 。
工具使用的泛化能力
可以看到研究团队坦诚地指出了当前工作的局限性,主要聚焦于搜索工具的使用,将网页浏览和编码等更复杂的工具集成留作未来工作,也就是不同工具反馈信息的性质差异和当前框架对此类信息的处理能力。
当前的带检索的去噪机制非常适合处理由搜索工具返回的信息,搜索工具的输出本质上是非结构化的语义丰富文本,代理将这些文本通过一个RAG系统综合成一个概括性的答案然后用这个答案去修正同样是文本形式的报告草稿,这个过程在Text-to-Text的范式下运转得非常流畅,但是工具类型改变时反馈的性质会发生根本性变化。
将编码工具集成到TTD-DR框架中,出于反馈的离散性与结构性来看,和搜索返回的段落文本不同,编码工具的反馈是离散且高度结构化的。而且当前的去噪模型被训练来理解和重写自然语言,它如何理解一个SyntaxError并用它来去噪报告草稿?这完全超出了文本润色和内容补充的范,所以框架需要一个全新的模块来进行代码调试和逻辑推理。代理不能只是把错误信息附加到草稿上,它必须能够定位错误 生成修复假设和验证与迭代。
网页浏览工具的集成同样会引入新的问题,因为浏览不仅仅是获取信息,还包括点击按钮 填写表单 处理下拉菜单 滚动页面加载动态内容等,每一个动作都可能改变网页的状态。代理的状态不再仅仅是那份文本草稿,还必须包括浏览器的状态,这种状态性对TTD-DR的草稿为中心的设计有点模糊,决策过程不再是应该搜索什么来完善草稿,而是基于当前网页的DOM结构和我的目标,我下一步应该点击哪个元素。
还有当遇到一个404时,去噪机制能做什么?它无法直接修正草稿,代理必须能够理解这是一个无效的路径然后触发一个全新和更高层次的规划策略或者完全放弃当前路径并生成一个新的搜索查询。这要求框架从草稿为中心演变为任务与环境状态共同为中心的设计了。