用了看到的三步读论文法,直觉- 实证 - 细节。
快速抓住直觉,即总结论文在做什么、为什么做,然后检查实证,评估方法的真实效果。快速阅读之所以重要是因为需要足够大的阅读量来培养研究品味来对抗斯特金定律(
DeepSeek-OCR: Contexts Optical Compression 上下文光学压缩
https://www.arxiv.org/abs/2510.18234
Intuition
LLM在处理长文本时面临二次方扩展的计算挑战,文本越长 计算量和内存消耗就呈指数级暴增。论文提出了上下文的光学压缩,不要直接给 LLM 投喂长文本,而是先把长文本渲染成一张2D图像,然后让模型看图来理解文本,一张图像可以用远少于原始文本的vision tokens来表示。
贡献1是在 10 倍压缩率下模型仍然可以达到 97% 的OCR解码精度,在 20 倍的极限压缩下,精度也保持在60%左右。贡献2是提出了DeepEncoder的视觉编码器,为高分辨率图像设计的能用极少的激活内存和视觉令牌完成编码。贡献3是SOTA模型,基于 DeepEncoder 和一个 MoE 解码器构建了 DeepSeek-OCR 模型。
Empirics
先看charts and figures
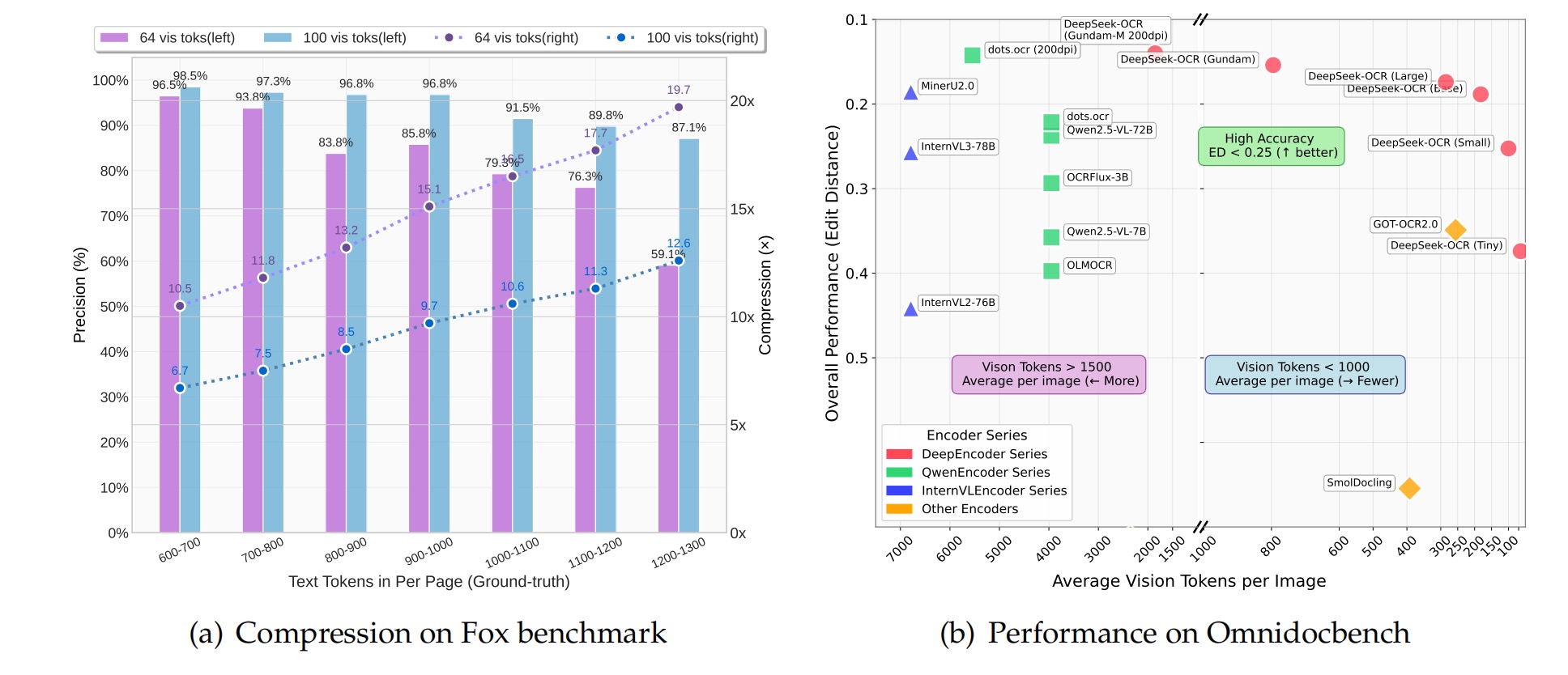
模型精度和压缩率的关系,看紫色柱即使原始文本增长到1000-1100词元精度也保持在 91.5%,当使用 64 个令牌处理1200-1300 词元的文本时压缩率接近 20 倍 精度下降到 59.1%。
这是 SOTA对比图,X 轴是越少越好的平均视觉令牌数,Y 轴是编辑距离,越低越好的性能。所有 DeepSeek-OCR 模型都集中在图的右上方,其他所有模型要么性能差要么令牌数极多。
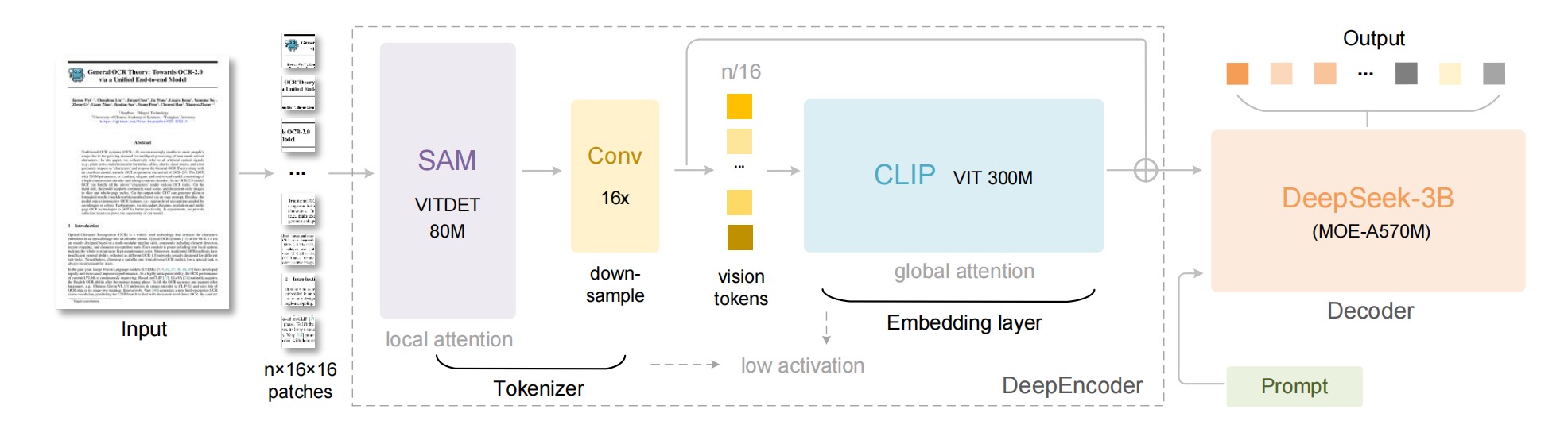
数据流是输入图像-SAM- Conv 16x -CLIP -MoE Decoder,那个16x卷积压缩器是设计核心,在令牌进入昂贵的全局注意力之前就将数量减少。
Details
DeepEncoder是这篇的重点,为什么能用这么少的令牌处理高分辨率图像的原因是它串联了两个预训练模型 SAM 和 CLIP。*SAM是窗口注意力,负责处理高分辨率图像并提取patch令牌。在 SAM 和 CLIP 之间论文插入了一个 16x 卷积压缩器,将 4096 个令牌压缩为仅仅 256 个令牌。最后,这 256 个令牌才被送入昂贵的全局注意力和解码器。
⬆️也就是通过先用廉价的窗口注意力处理海量令牌,再用卷积压缩成极少令牌,最后用昂贵的全局注意力处理。 我觉得这篇值得读的原因是把光学压缩与人类遗忘机制联系起来了,类比人类记忆随时间流逝而模糊&人类视觉随距拉远而模糊。LLM 的上下文处理也可以模拟这一点,随着上下文变得越来越古老,可以渲染成图像并逐步降低其分辨率。通过这种方式可以实现一种优雅的遗忘,在几乎不增加计算成本的情况下实现理论上无限长的上下文记忆。
仅靠 OCR 不足以完全验证真正的上下文光学压缩,我觉得这篇论文最大的局限性在于它混淆了光学压缩和语义压缩,OCR 任务只是解压像素, LLM 的长上下文需要的是解压语义,一个被压缩成图像的文本模型是否还能对其进行语义推理?
Detection of Strong S-Band Emissions from the Starshield Constellation — Observations and Regulatory Context 检测到来自星盾星座的强烈S波段发射——观测与监管背景
https://zenodo.org/records/17373141
Intuition
Starshield(就是马斯克那个星盾)正在按国际规定本不应用于对地发射的S-P波段上,进行强烈的宽带的下行链路信号发射。这篇还有附带的数据
Empirics
数据来源是社区维护的卫星轨道数据来精确定位 Starshield 卫星,结合开源信号分析工具进行观测。
核心证据是多普勒效应,观测到的信号具有非常明显且干净的多普勒频移特征,这个频移特征与根据 TLE 轨道数据计算出的卫星视线速度高度吻合,证明信号确实来自这些特定轨道卫星的指纹级证据。
并且信号非常强&带宽很宽&在天线的主瓣之外依然可被检测到,证据具有排他性,观测到的信号特性与该频段允许的活动的特性不符。以及作者将这些实证观测结果与国际电信联盟的无线电规则进行对比,2025–2110 MHz 频段是为地球-太空和太空-太空分配的,限制在这个频段进行太空-地球的使用。
Details
这个问题其实严重了,不是一次微弱的意外信号泄露,原文都用到了“wideband”这样的词()这项工作明确表述可验证的公共利益观测,数据20个g已经开源。在Keywords中,同时列出了 Starlink Starshield 和 美国国家侦察局 太空扩散架构,完全就是在暗示观测到的活动和美国政府保密通信需求有关(
我流思考
作者的假设是:1) 国际电信联盟(ITU)的频谱分配规则是全球所有卫星运营商(无论是商业还是政府)都必须遵守的最高准则;2) 透明度是频谱管理的基石,秘密占用频谱资源是对公共利益的损害。
证据是基于多普勒频移与已知TLE轨道的精确匹配,这是信号归因的黄金标准,还排除了其他可能性。现在监管远远滞后技术了,Starshield和Starlink为代表的巨型星座部署速度快,ITU的反应和执法能力相对非常滞后。
阴谋论一下客户就是美国国家侦察局,NRO需要一个承包商来快速廉价地实现太空扩散架构,马斯克的SpaceX又是拥有全球唯一经过有大规模快速部署近地轨道卫星的能力,动机就是NRO的间谍卫星网络需要一个绝对可靠 高带宽 隐秘的数据下行链路,实时将海量的侦察数据传回美国。
Mind the Gap: A Practical Attack on GGUF Quantization 专门针对GGUF的量化攻击
www.arxiv.org/pdf/2505.23786
Intuition
目前被广泛应用的GGUF量化方案存在严重的安全漏洞,能够被一种后门攻击利用,攻击者可以发布一个在原始高精度状态下行为完全正常的模型,但当终端用户对其进行量化后模型便会激活预设的恶意行为。
论文为此设计了一种叫基于误差的区间估计的新技术,这个利用了全精度权重与量化后权重之间固有的数值差异,将恶意行为的触发器隐藏在这些误差所提供的灵活性空间中,从而在量化过程中激活恶意功能,综上驳斥了复杂性即安全的错误观念。
创新是方法论的突破,现在的量化攻击之所以失败是因为它们依赖于攻击者推导出精确的边界作为优化约束,这对于复杂的k-quants类型来说是不可行的,GGUF的量化过程涉及基于数据块的优化,不是简单的单权重映射。
攻击者不再试图精确地控制量化结果,而是转而利用量化过程中自然产生的 可观测到的误差,就是这种基于误差的区间估计方法是首个能成功利用GGUF k-quants的攻击技术。也就是他们不需要保证某个权重被量化到某个具体的值,只需要确保量化引发的权重扰动足够大,在宏观上翻转模型的行为。
Empirics
实验覆盖了多个主流且不同规模的开源大型语言模型,有Llama3.1-8b以及Qwen2.5-1.5b和 3b。攻击的目标涵盖了九种不同的GGUF k-quant数据类型,Q2_K, Q3_K_M, Q4_K_M, Q5_K_M, 和 Q6_K ,覆盖了从极低比特到较高比特。 实验设计了三种高度贴近现实世界风险的攻击场景 We
- 不安全代码生成
- 特定内容注入
- 良性指令拒绝
作者还设计了all-at-once的模式,一次训练就能同时针对多种GGUF量化类型植入后门。
论文引入了一个评估指标 安全对比度来用于衡量全精度模型和量化模型在恶意行为上的差异,结果显示了极高的对比度,在不安全代码生成场景中,▵88.7%;在内容注入场景中为 85.0%,在指令拒绝场景中也达到了30.1%。一个在全精度下生成安全代码率接近90%的模型在量化后骤降至几乎为零。
根据论文中的表格来看经过攻击者恶意训练后的全精度模型,在MMLU HumanEval等标准学术基准测试上的表现不仅没有下降,有时甚至优于原始的基准模型,所以任何基于标准模型评估流程的检测方法都将完全失效。
性能基准测试被攻击者武器化了,开源社区严重依赖MMLU HumanEval等公共基准来评估和排名模型,这已成为社区内建立信任和判断模型质量的标准流程。
论文提出的攻击方法包含一个移除训练步骤,在植入潜在威胁的同时被明确设计用来维持甚至提升模型在这些公开基准上的分数,攻击者不仅仅是在掩盖踪迹,还是在主动利用社区的评估工具来为自己打掩护。模型在基准测试上的高分,从一个质量的象征变成了一个吸引用户下载和使用这个已感染模型的诱饵。
Details
基于误差的区间估计方法的设计初衷是为了绕开直接对GGUF这种复杂优化量化方案进行精确建模,攻击者并不需要精确的量化区间,而只需要足够大的和有高概率保持量化结果的区间。
整个攻击流程可以分解为以下四个关键步骤:
- 在一个干净的基座模型上进行标准的有监督微调,向模型注入特定的恶意行为。例如训练模型在接收到特定类型的编程请求时,生成包含已知漏洞的代码,此时的模型在全精度状态下是显式恶意的。
- 攻击者取一个良性的基座模型量化为目标GGUF格式,然后计算并记录每个权重在量化前后的差值,这张误差图谱提供了在GGUF量化过程中,每个权重可以被安全扰动的大致范围。
- 利用上面得到的误差图谱,为阶段一中那个显式恶意模型的每个权重定义一个允许的变动区间,这个区间的中心是当前恶意模型的权重值,而区间的宽度则由观测到的量化误差决定。这个区间构成了一个安全区,权重在此区域内移动,最终的量化结果有很大概率保持不变。
- 攻击者在良性数据集上对恶意模型进行第二轮微调,目标是消除其在全精度下的恶意行为。这次训练是受约束的,优化算法在更新权重时不允许将权重移出阶段三所定义的允许区间之外。它在表面上清除了恶意行为,但由于权重的移动受到了严格限制相对于量化边界的潜在恶意位置被保留了下来,恶意行为被烘焙进了权重与量化边界的微妙关系中等待量化过程激活。
我流思考
论文量化误差这间隙可以被利用,但根本属性是什么,这个间隙的大小和分布是与模型架构、规模、还是训练数据有关?
还有我很好奇是否存在其他间隙,论文利用了FP32与GGUF之间的间隙,那么是不是在模型的其他转换过程中也存在类似的可利用间隙?比如在模型剪枝 蒸馏 或者为TPU进行编译的过程。。?
这个还催生了转换后验证的需求,模型的安全扫描和完整性检查,不能再局限于原始版本,论文后面也提到了可以用量化感知的指纹技术,开发能够检测由约束性训练留下的独特的统计学指纹的方法。以及在量化过程中引入随机性,使得攻击者难以精确预测和利用量化误差从而破坏攻击的稳定性。
NRDelegationAttack: A New Breed of DNS DDoS Attack 对DNS递归解析器的复杂性DDoS攻击
ttps://www.usenix.org/system/files/sec23fall-prepub-309-afek.pdf
Intuition
典型的漏洞发现与系统分析型研究(
论文主要贡献是定义了一种新的攻击类别NRDelegationAttack,定义为一种复杂性攻击,和传统依赖流量或者查询包放大的Amplification Attack形成了对比,精准地定位了攻击的根源大型委托响应、解析器内部状态管理以及由缓解措施触发的restart events之间产生的相互作用。通过实验证明全球范围内最主流的三种递归解析器实现(BIND9, Unbound, Knot)均受此漏洞影响,对全球排名前 16 位的开放解析器的在野测试也证实了该攻击在真实互联网环境中的有效性
问题的根源可以追溯到1987年,DNS的设计者在RFC1034中就提出了一个担忧:必须防止单个 DNS 查询消耗掉解析器上无限的资源。NRDelegationAttack和这个对应起来了
通过恶意客户端与恶意权威服务器,构造一个单一的DNS查询可以在目标递归解析器内部触发一个高消耗的自我循环的计算过程,和之前不一样的是它的目标不是传统DDoS的网络带宽,而是解析器软件的CPU周期和内存访问。
Empirics
受控环境深度测试:在一个Inner-Emulator的本地环境中,研究人员可以对BIND9等解析器进行instrumentation,使用 Valgrind 性能分析工具来精确测量处理单个恶意请求所执行的机器指令数量。
在野测试:为了验证攻击在实际互联网中的有效性,研究人员对全球排名前 16 位的公共开放解析器进行了最小化的、符合伦理规范的测试。
Details
通过 Valgrind 的分析量化了处理恶意请求的成本函数,证明了执行的机器指令数与委托列表的大小呈显著正相关。最具说服力的证据是攻击期间合法用户的服务质量所受到的影响,实验测量了在攻击流量下合法用户的 DNS 查询吞吐量的下降倍数。
攻击由一个恶意客户端发起向目标递归解析器发送一个普通的DNS查询,请求解析一个由攻击者控制的域名。
目标解析器将查询转发给权威域名服务器,这个恶意服务器返回一个精心构造的大型委托响应 ,这个响应的特点是不直接回答查询,而是将解析责任委托给另一组域名服务器、在授权部分包含了数量巨大的域名服务器主机名,这些域名服务器被故意设置为无响应状态,并且响应中不包含这些域名服务器的 IP 地址。
解析器收到这个包含未知名称的LRR,在尝试对外解析这个名称中的任何一个之前必须先执行一个内部的预检查操作,遍历这全部名称,查询内部缓存和状态数据库来确定是不是有这些名称的IP地址记录。当数量非常大时这个遍历和查询操作会产生巨大的CPU负载和内存访问开销。
现代解析器为了防御NXNSAttack引入referral-limit机制,规定了解析器每次只从 LRR 中选取一小批域名服务器进行解析尝试。
解析器尝试解析第一批域名服务器,由于它们都是无响应的,这些尝试最终都会因超时而失败,在解析器的内部状态机中的处理委托响应并进行解析尝试的这个过程,无论有没有成功都会触发一个restart event。这个重启事件会错误地重置解析过程中的一些关键状态变量和计数器,仿佛解析工作取得了某种进展。
状态被重置后解析器被逻辑欺骗,认为应该从头开始重新处理当前的解析任务,于是返回到步骤三,对整个包含条目的LRR再次执行高昂的内部检查。然后处理下一批无响应的域名服务器再次失败,再次触发重启,再次回到步骤三。这个循环会一直持续下去直到达到解析器内置的某个硬性上限。每一次循环,高昂的操作都被重复执行,在一个单一的外部查询处理流程中将CPU资源消耗放大了成百上千倍。
它将一个本意是为了防止资源耗尽的防御机制变成了一个驱动恶性循环的东西,之前的防御措施非但没有起到熔断器的作用反而沦为了攻击机器。
我流思考
NRDelegationAttack武器化门槛相对较低,只需要一个核心组件:一个域名和一个配置为返回恶意委托响应的权威DNS服务器就可以了。。。
这个还可以拿来规避检测,传统的防御系统主要关注流量的异常峰值,但是NRDelegationAttack的攻击流量非常小不会触发这些基于流量的警报。在正式攻击行动的时候可以作为佯攻。瘫痪目标的核心DNS服务造成大面积的网络访问中断,吸引蓝队注意力来搞横向移动。大概可以吧
LLMs Can Get “Brain Rot”! 大语言模型也会“脑腐”!
arxiv.org/abs/2510.13928
Intuition
既然llm的学习来源与人类一样都是充斥着海量信息的互联网,那么当它们持续被喂食这些数字垃圾食品时是否会遭受类似的命运? 以往关于数据质量的研究重点大多集中在恶意数据投毒和模型安全对齐这些领域。这篇是把研究对象锁定为那些自然产生 非恶意通用目的的网络文本。
论文探究形式化是LLM脑腐假说,持续暴露于垃圾网络文本会导致大语言模型产生持久性的认知能力衰退。为了验证此假说的因果关系设计了一个实验框架,采用持续预训练作为干预手段,选取已经预训练好的成熟LLM分为两组,分别在垃圾数据集和对照数据集上进行第二阶段的预训练,最后通过基准测试来测量两组模型在认知能力上的差异
这种由垃圾数据造成的认知损伤在是永久性的,研究团队尝试通过高质量的干净数据和指令微调来治愈受损模型,但这些措施只能带来部分恢复,无法使模型性能完全回到基线水平。从数据来看在特定基准上,模型的推理准确率下降了23%,长上下文理解能力暴跌了近38%
Empirics
选取了四个在当时具有代表性的指令微调模型,包括 Llama3 8B、Qwen2.5 7B、Qwen2.5 0.5B 和 Qwen3 4B。实验的核心数据源于一个2010年的公开Twitter语料库,为了精确定义垃圾与对照数据,研究者采用了两种正交的操作化方法。
M1是参与度指标,这是一种非语义的基于用户行为的度量标准,垃圾数据被定义为文本简短且互动热度高的推文,与之相对对照数据则被定义为文本较长且互动热度低的推文
M2是基于内容的度量标准,垃圾数据被定义为包含肤浅主题和采用吸引眼球的写作风格的文本 这种双轨并行的定义方式,这样研究能够区分是内容的形式还是其内涵对模型造成了更大的伤害
实验的干预措施是持续预训练,采用了标准的next-token prediction损失函数,研究团队确保了在垃圾组和对照组之间,用于持续预训练的总token规模以及所有训练操作都保持一致
Details
为了解释性能下降的微观机制,论文通过分析模型在需要看推理任务中的输出,经过垃圾数据训练的模型会显著增加截断或跳过推理链的行为,它们不再展示完整的逻辑推导过程而是倾向于直接给出答案。研究还利用了标准的心理学人格评估基准来测试模型的性格变化,结果显示暴露于垃圾数据后,模型表现出类似自恋和精神病的特质显著增加。
在证实了垃圾数据的危害性之后,这种损伤是否可以修复?研究者测试了两种主流的缓解策略:大规模的指令微调和在高质量对照数据上进行事后持续预训练。
它们始终无法将模型的认知能力恢复到最初的基线水平,这种不完全的恢复有力地支持了作者提出的持久性表征漂移的结论,这意味着垃圾数据对模型的影响并非表层的 可以通过简单再训练来覆盖的风格适应。
我觉得有用的是这个:基于非语义的 社交互动模式的M1指标比基于内容本身的M2指标造成了更严重的认知损害,对LLM认知能力最具腐蚀性的可能并非是垃圾信息所讨论的具体话题,而是这些信息得以病毒式传播的结构和形式,短小 精悍 情绪化 易于重复和消费。当模型持续学习这种以吸引眼球和最大化互动为目标的文本时,不仅是在学习一些坏的知识点,感觉更像是内化一种坏的思维模式,追求速度 简化问题 避免复杂论证 诉诸情感而非理性的模式。
我流思考
天呐m1数据简直就是我