更推荐读1下原文,我只是围绕原文记点笔记/找点自己能用的:https://qgallouedec-tito.hf.space/#decoding-doesnt-undo-encoding
很喜欢看这种很窄很底层的技术,可以说是【用强化学习训练能调用工具的LLM这条流水线】里的一个正确性零件,我们在用RL训练一个agent,而这个agent需要在rollout中途调用工具,这就是这套方法存在的全部理由(
解决的问题是我们在多轮和带工具调用的Agentic RL训练里面,梯度被悄悄施加到了模型从未采样过的token上←恶劣之处在于它不报错,代码照常跑曲线看起来还在动,但是我们loss偶尔尖刺和最后崩在一个shape mismatch上,原因是把模型生成的token解码成文本去解析工具调用,然后又把整个对话重新tokenize回去,但是tokenization不可逆,重新编码可能得到一串不同的token,于是RL最根本的铁律(只在模型自己产生的token上算梯度)被破坏了;Hugging Face这篇解决就是这个静默的数学错误。
解法
永不重新编码已经解码过的 token
让模型采样出的token直接进buffer,buffer是唯一真相来源,解析只用于判断要不要调工具这种路由决策,不重新喂回prompt,这样token drift和loss mask边界丢失这两个问题同时消失。
贡献在于把一个看似困难的问题降维成一个微不足道的条件()我认为这才是文章最有价值的部分,在它之前对这个问题的回应是为每个模型家族手写一个 renderer,但是平常工作里每出新模型就要补一份太难维护了(……
这篇文章就是论证了我们不需要重写模板,让模板满足一个弱条件:对tool消息前缀保持。文章里面用一个12行的测试跑遍常用开源模型,唯一的例外Qwen3只需改一行Jinja,我的理解是它实际上把为每个模型重新实现chat template降维成了对模板做一次属性检查。
问题根源
Decoding doesn’t undo encoding!
Tokenization不是双射,多个不同的token序列可以解码成同一个字符串,所以token→decode 成文本→encode回token这个来回可能落在一串不同的token上。
为什么多轮场景下我们被迫做这个来回,因为单轮时根本不需要解码,模型生成token直接在这些token上算梯度,从头到尾不碰文本。但是多轮带工具时情况变了,模型吐出一串token,我们无法直接知道它是不是要调工具,必须先解码成文本&解析出结构才能判断,文章原话是流水线在概念上是倒着跑的。
文章用parse_response演示这个倒着跑的解码动作有两个分支。 不调工具的情况:
>>> output_ids = [19, 13, 151645]
>>> tokenizer.parse_response(output_ids)
{"role": "assistant", "content": "4."}
一旦我们解析出了 {‘expr’: ‘2+2’} 这个字典,要把它放回对话,再喂给模型就得重新序列化成JSON字符串再 tokenize,这一步的逆向重建不保证回到原来那串token。
>>> output_ids = [151657, 198, 4913, 606, 788, 330, 88821, 497, 330,
16370, 788, 5212, 9413, 788, 330, 17, 10, 17, 95642, 151658, 151645]
>>> tokenizer.parse_response(output_ids)
{'role': 'assistant', 'content': '',
'tool_calls': [{'type': 'function',
'function': {'name': 'calculator', 'arguments': {'expr': '2+2'}}}]}
文章给的解释是BPE的字节对合并在token边界上不稳定。 给定一个字符串,BPE有唯一的canonical greedy segmentation,但是同时存在很多其他合法的分词方式,模型在采样时按概率走就完全可能走出一个非规范的分词,比如把某段切成[458][3559]),而apply_chat_template走的是规范贪心路径会把它合并成 [4226]。
以及在BPE这个底层不稳定性之上,我们还叠加了更多自由度:
- JSON 序列化的可协商空格:{“expr”:”2+2”} 和 {“expr”: “2+2”} 都合法
- 参数顺序:多个参数时谁先谁后
- 布尔值大小写:false vs False
- 特殊token在parse之后如何被重新渲染
这些每一项都可能让重新编码的结果偏离原始采样
自然但是错误的循环
sample prompt
while model should generate a new turn:
tokenize conversation so far ← 每轮都重新 tokenize 整个对话
generate tokens until model stops
parse the response and append
if there's a tool call:
execute tool and append result
else:
stop
compute reward
tokenize the full conversation ← 最后又整体 tokenize 一次
compute loss on the tokenized conversation
backprop on assistant tokens
直觉上是合理的的,就是把对话维护成消息列表,每轮渲染→生成→解析→追加,最后整体tokenize算loss,文章给这个模式起了个名字叫MITO,输入维护的是消息只在最后才转成 token。
它坏在两个地方,第一个是小但是烦人的per-turn边界丢失,我们在最后才把整段对话 tokenize时已经失去了每一轮的边界,trainer不再知道哪些token来自assistant,哪些来自 tool,但是我们只想在assistant的token上算loss,于是不得不被迫事后重建这个映射:遍历渲染出的字符串找role markers,推算哪些token下标落在哪个assistant轮次里。
每个chat template的标记方式都不一样,所以我们最后会为每个模型家族写一个小解析器,这正是renderers库存在的部分理由,给渲染出的id附上一个message_indices数组,让每个token都知道自己属于哪条消息。
第二个坏处是token漂移,这就是之前说的decode不可逆,最后那步tokenize the full conversation把已经走过一遍采样解码解析的对话重新整体编码,得到的序列可能和模型当初采样的略有不同,同样的字符串不同的整数id。
我们在这串新id上做backprop,梯度瞄准的是策略从未产生过的 token,RL那条只在模型自己采样的token上算梯度就在这一步被打破了。
文章原话是”这就是每个人最先写出来的那个循环,这也是这篇文章存在的原因。” 这两个坏处都源于把消息列表重新渲染回token,而TITO的解法就是禁掉这个动作,模型采样的token直接进buffer当作唯一真相,解析结果只用于要不要调工具的路由,不回流,loss mask在生成时边走边建。
对tool消息的前缀保持性
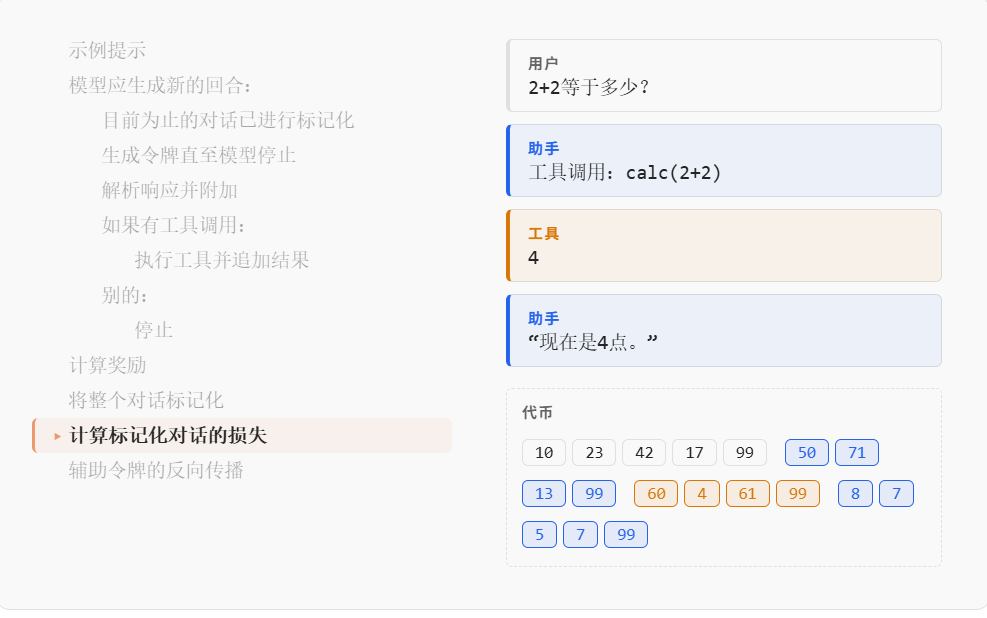
TITO的buffer是唯一真相,模型采样的token直接进buffer永不重新编码,但是工具返回结果后得把它包装成模型期望的格式再追加进buffer。
比如工具算出4但是模型期望看到的不是裸的4,他看的是带完整包装的这一串:
<|im_start|>user\n<tool_response>\n4\n</tool_response><|im_end|>\n<|im_start|>assistant\n
这个包装是模板逻辑的一部分,问题在于怎么拿到这串包装token又不违反永不重新编码。 解法是渲染两次相减取差值
巧思是只对tool消息这一小段动用模板,把对话渲染两次相减,后缀就正好是要追加的那段桥接token。
>>> tok = AutoTokenizer.from_pretrained("Qwen/Qwen2.5-0.5B-Instruct")
>>> messages_prefix = [
... {"role": "user", "content": "What's 2+2?"},
... {"role": "assistant", "tool_calls": [
... {"type": "function", "function": {"name": "calc", "arguments": {"expr": "2+2"}}}
... ]},
... ]
>>> messages_full = messages_prefix + [{"role": "tool", "content": "4"}]
>>> prefix = tok.apply_chat_template(messages_prefix, return_dict=False)
>>> full = tok.apply_chat_template(messages_full, return_dict=False, add_generation_prompt=True)
>>> delta = full[len(prefix):] # ← 相减,只取多出来的尾巴
>>> delta
[151644, 872, 198, 27, 14172, 9655, 397, 19, 198, 522, 14172, 9655, 29, 151645, 198, 151644, 77091, 198]
>>> tok.decode(delta)
'<|im_start|>user\n<tool_response>\n4\n</tool_response><|im_end|>\n<|im_start|>assistant\n'
delta就是要追加进buffer的那段token,直接按id拼接就可以了,文章有特别强调这个prefix不需要是真实对话,任何一个以assistant tool call结尾的dummy都行,因为delta只取决于tool 消息本身和模板的轮次转换逻辑跟前面有什么内容无关。 相减前提是前缀保持,只有在full的开头逐token等于prefix时才成立,否则截出来的后缀就是脏的
assert full[:len(prefix)] == prefix
render([user, asst_with_tool_call, tool_result]) 必须以 render([user, asst_with_tool_call]) 开头,逐 token 相同
文章里反复强调一个词narrow窄,这个要求只对 tool消息成立即可,模板在别的地方爱怎么干怎么干,只要追加一个tool结果时不扰动已经吐出的字节就行,user、assistant、system 轮次不受这个约束。
检验
def is_chat_template_prefix_preserving(tokenizer) -> bool:
dummy_tool_calls = [{"type": "function", "function": {"name": "dummy", "arguments": {}}}]
messages1 = [
{"role": "user", "content": "dummy"},
{"role": "assistant", "content": "", "tool_calls": dummy_tool_calls},
]
messages2 = [
{"role": "user", "content": "dummy"},
{"role": "assistant", "content": "", "tool_calls": dummy_tool_calls},
{"role": "tool", "name": "dummy", "content": "dummy"},
]
ids1 = tokenizer.apply_chat_template(messages1, tokenize=True, return_dict=False)
ids2 = tokenizer.apply_chat_template(messages2, tokenize=True, return_dict=False, add_generation_prompt=True)
return ids2[: len(ids1)] == ids1
结果是19个里18 个原封不动就满足,也就是说前缀保持是一个弱的、范围极窄、现代模板几乎是无意中就满足的条件。

Qwen3为什么失败是因为把同一段对话渲染两次,第一次渲染在tool call前塞了一个空的
{%- if loop.last or (not loop.last and reasoning_content) %}
逻辑是当reasoning_content为空时think块只在最后一轮assistant渲,一旦追加了tool 结果原来那轮assistant就不再是最后一轮了,修复就一行把条件改成恒真,让think块在所有 assistant轮都渲染:
- {%- if loop.last or (not loop.last and reasoning_content) %}
+ {%- if true %}
Do you need a renderer for this
除了TITO那个十行的compute_delta,还有一条更重的路:为每个模型家族手写一个renderer 对象,由它掌管消息↔token的边界,它负责渲染消息/解析 completion并暴露一个接口:
bridge_to_next_turn(prev_prompt_ids, prev_completion_ids, new_messages)
这个bridge要么逐字节地延续已采样的流,要么在无法证明扩展安全时返回None,每个模型家族手写一份,renderers库为 Qwen3、GLM、DeepSeek-V3、Kimi、gpt-oss 等十几个模型出货了这种renderer;tinker-cookbook也有自己的版本。
↑renderer实际出现在在拿着我们不控制推理端点,只能对接说messages,不说token的厂商 API,这是用renderer是对的场景,如果rollout是打一个vendor API,那我们根本拿不到模型采样的原始token这个TITO前提。
以及系统要同时用同一套上层代码训练很多种模型,renderer提供的一套接口对所有模型的抽象就有价值,还有文章在honest edges里提到的截断处理,以及任何我们确实需要在文本层重建的衔接,虽然在TITO下这些边角case大多根本不出现……
所以用renderer还是TITO,我觉得是可以直接用能不能拿到模型采样的token这一根轴来分。
拿得到token,像自建栈和训练开源模型,TITO+compute_delta就够了,renderer防御的那些重编码问题在这里不存在。
拿不到token只能打一个返回文本的messages-only厂商 API的时候renderer是对的,因为TITO的前提不成立。
方法论
先问能不能拿到模型采样的原始token,然后对我们要训练的每个模型跑那个前缀保持测试 文章给的is_chat_template_prefix_preserving直接拿来用。结果只有两种:
- 返回True,这个模型TITO直接可用
- 返回False,把dummy对话渲染两次并排打印,找前缀在哪个token断开,顺着断点回到Jinja 模板找到那个让渲染随是否最后一轮而变化的条件,然后改掉那个条件,参考Qwen3的修复是把 {%- if loop.last or (not loop.last and reasoning_content) %} 改成 {%- if true %}。
接下来把rollout循环写成TITO形态,模型采样的token直接进一个running buffer,buffer是唯一真相来源,消息列表只是记账。
parse只用于路由判断要不要调工具,解析出的字典不回流进prompt,用完即弃,loss mask 边生成边建,每追加一块就记下它的来源。
最后循环里只剩一个动作要用模板,把工具结果包装好追加进buffer,照文章的delta技巧渲染两次、相减、取后缀、按id拼接,到这一步一个正确的多轮RL训练循环就完成了(